|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
*****
На этом мы закончим с общим обзором поиска по дереву вариантов, который начался еще в I части. В VI и VII частях мы снова вернемся к нему, обратившись к конкретной реализации перебора на примере кода программы Стокфиш. Пока же я могу предложить вам самостоятельно посмотреть код программ попроще.
Ниже я дам ссылку на ряд версий программы разработанной Игорем Коршуновым (WildCat), которые он выкладывал в свое время на форуме Иммортала. В архиве находятся версии за весь цикл разработки, от программы действительно полного перебора, до версии уровня намного сильнее чемпиона мира. Все ранее рассмотренные методы в наиболее продвинутой версии присутствуют. Есть и кое-что еще.
Поскольку Игорь приложил к коду проекты для VisualC++, то с кодом может повозиться даже человек не умеющий программировать. По крайней мере с оценочной функцией (файлы Eval) или с поиском (файлы Search).
https://drive.google.com/file/d/1R0hBvoVtWkXN8DTXnl5ROpZL3cd1iok0/view
В архиве есть не только код, но и исполняемые файлы. Для визуализации ходов потребуется графическая оболочка (GUI), простейшую из которых я тоже положил в архив. Связь между GUI и движком осуществляется по UCI-протоколу, но вам знать его не обязательно. Надо только указать в оболочке путь к файлу программы.
https://drive.google.com/file/d/1CHshNGVDWAOaKjhtngSHZ_8XjsINiWLY/view
Общую информацию по более продвинутым оболочкам можно получить на вики страницы разработки Стокфиша на гитхабе:
https://github.com/official-stockfish/Stockfish/wiki/Download-and-usage#download-a-chess-gui
Наиболее популярными и универсальными среди них являются бесплатная Arena и коммерческий Fritz (от ChessBase). Для тестирования и игры программ между собой лучше подходят простая CuteChess или более продвинутая Banksia. Там же на гитхабе Стокфиша можно найти и некоторые наборы стартовых позиций, чтобы разнообразить начала партий:
https://github.com/official-stockfish/books
Всякая интересная информация по ссылке:
https://github.com/official-stockfish/Stockfish/wiki/Useful-data
Ну а мы пока перейдем к разбору типичной оценочной функции.
Продолжение следует... |
|
|
| номер сообщения: 54-72-8256 |
|
|
|
|
Шахматные программы V. Оценочная функция
В этой части мы рассмотрим вторую важную составляющую шахматных программ - оценочную функцию. Долгие годы она находилась в роли "пасынка" для процесса разработки. Но на то существовали объективные причины.

После того как в первые десятилетия истории компьютерных шахмат программисты реализовали в оценочной функции простейшие и легко вычисляемые признаки позиции, дальнейшие улучшения столкнулись с трудностями. Даже периодически приглашаемые шахматисты самой высокой квалификации оказались бессильны помочь. Несмотря на многократные попытки, они не смогли предложить какие-либо важные признаки позиции, которые давали бы больше пользы, чем требовали вычислений. |
|
|
| номер сообщения: 54-72-8257 |
|
|
|
|
Используемая программами "рукописная" оценочная функция на основе выделенных параметров состояла из материальной и позиционной составляющей. Первая заключается в подсчете количества фигур на доске, своих и соперника. Вторая учитывает их взаимное расположение.
С годами уровень оценочной функции все же постепенно возрастал. Понемногу увеличивалось количество определяемых признаков позиции. Оценка была разбита на две части - миттельшпильную и эндшпильную, которые смешивались пропорционально перехода позиции в партии от одной стадии к другой. Были найдены методы автоматического тюнинга "весов" параметров, путем наигрывания большого количества партий программы с самой собой. Но все равно улучшения были плавными и относительно небольшими.
Уровень оценки резко подрос в недавние годы с появлением нейросети NNUE, которая заменила "ручную" оценочную функцию. Новая структура оценки была заимствована из японской игры сеги, где разработчики программ наткнулись на идею принципиально иной архитектуры на базе нейросети, тонко адаптированной к текущим возможностям программ и железа.
Тем не менее и в настоящее время, в основном из-за аппаратных ограничений, не удается задействовать все вычислительные ресурсы доступные программам, а значит и все возможности нейросетей. В частности, по-прежнему нельзя производить вычисления на видеокартах. Поэтому уровень оценочной функции все еще остается недостаточным. Но это в свою очередь оставляет огромный запас для дальнейших улучшений, все предпосылки для которого уже существуют. Есть вычислительные мощности, известны лучшие архитектуры сетей и методы их обучения. Если только ключевые препятствия будут сняты, сила оценочной функции может возрасти многократно. |
|
|
| номер сообщения: 54-72-8258 |
|
|
|
|
*****
Начнем мы с краткого обзора классической "ручной" функции оценки. В наше время многие программисты, начиная писать свой движок с нуля, все еще предпочитают ставить ее в качестве "заглушки", занимаясь в первую очередь написанием и отладкой базовой части программы с битбордами, генератором ходов и классическим поиском.
Как уже сказано выше, оценочная функция состоит из материальной и позиционной составляющей. В материальной части каждой фигуре присутствующей на доске назначена определенная цена, выраженная обычно в сантипешках. Разница ценности фигур своих и соперника дает материальную оценку.
При подсчете позиционных факторов наиболее важными являются таблицы ценности полей (Piece-Square Tables, PST, PSQ, PSQT). Они назначают бонус или штраф к цене фигуры в зависимости от ее положения. Для примера, конь на краю доски получает минус к оценке позиции. В простейших программах PST, это обычно несколько таблиц, с коэффициентами на определенных координатах, для каждого типа фигуры.
Другие значимые факторы, которые считает ручная оценочная функция, это обычно защита короля, различные виды оценок для пешечной структуры - проходные, сдвоенные, изолированные пешки и т. д. Программа определяет так же открытые линии для ладей, мобильность слонов (количеством доступных им полей). Кроме того учитываются очередность хода, пара слонов и. т. д. В более продвинутых версиях оценки могут вводиться нелинейные корректировки для дисбалансного материального соотношения. Каким образом учитываются эти факторы, можно посмотреть в старых программах, в том числе той, которая рекомендуется в конце IV части.
Реализацию классической оценочной функции в предыдущих версиях Стокфиша можно посмотреть на странице:
https://hxim.github.io/Stockfish-Evaluation-Guide/
Как мы видим, оценка в ней состояла из двух частей, соответствующих стадиям середины и конца партии. Вклад каждой стадии в общую оценку вносился пропорционально, в зависимости от количества материала оставшегося на доске. По мере перехода от миттельшпиля к эндшпилю "вес" первой составляющей в общей оценке постепенно уменьшался, а второй соответственно возрастал. Оценка каждой стадии вычислялась путем суммирования примерно десятка отдельно вычисляемых позиционных факторов, в основном тех, что указаны выше.
Оценочная функция тюнинговалась вручную или с помощью метода SPSA (Simultaneous Perturbation Stochastic Approximation), путем проведения множества партий программы с самой собой и постепенного подтягивания весов каждого параметра к оптимальным значениям. Для оптимизации параметров поиска этот метод используется и сейчас. |
|
|
| номер сообщения: 54-72-8259 |
|
|
|
|
*****
В настоящее время во всех ведущих программах на классической базе для оценки позиции используется нейросеть на основе оригинальной архитектуры NNUE. Ее впервые предложили японские разработчики. Изначально она применялась для программ игры сеги и представляла собой линейную функцию из одного гигантского слоя. Позднее авторы программ сеги добавили на его выходе нелинейные преобразования и пару небольших дополнительных полносвязных слоев, поверх первого, что превратило эту систему в нейросеть. После сокращения размерности первого слоя, в таком виде она перекочевала в обычные шахматные программы летом 2020 года.
Эта архитектура превосходно адаптирована к вычислениям на современных CPU. К сожалению, программы на классической базе не в состоянии использовать гораздо большие мощности GPU. Как уже упоминалось ранее, этому скорее всего препятствует слишком большая задержка при передаче данных между центральным процессором и видеокартой.
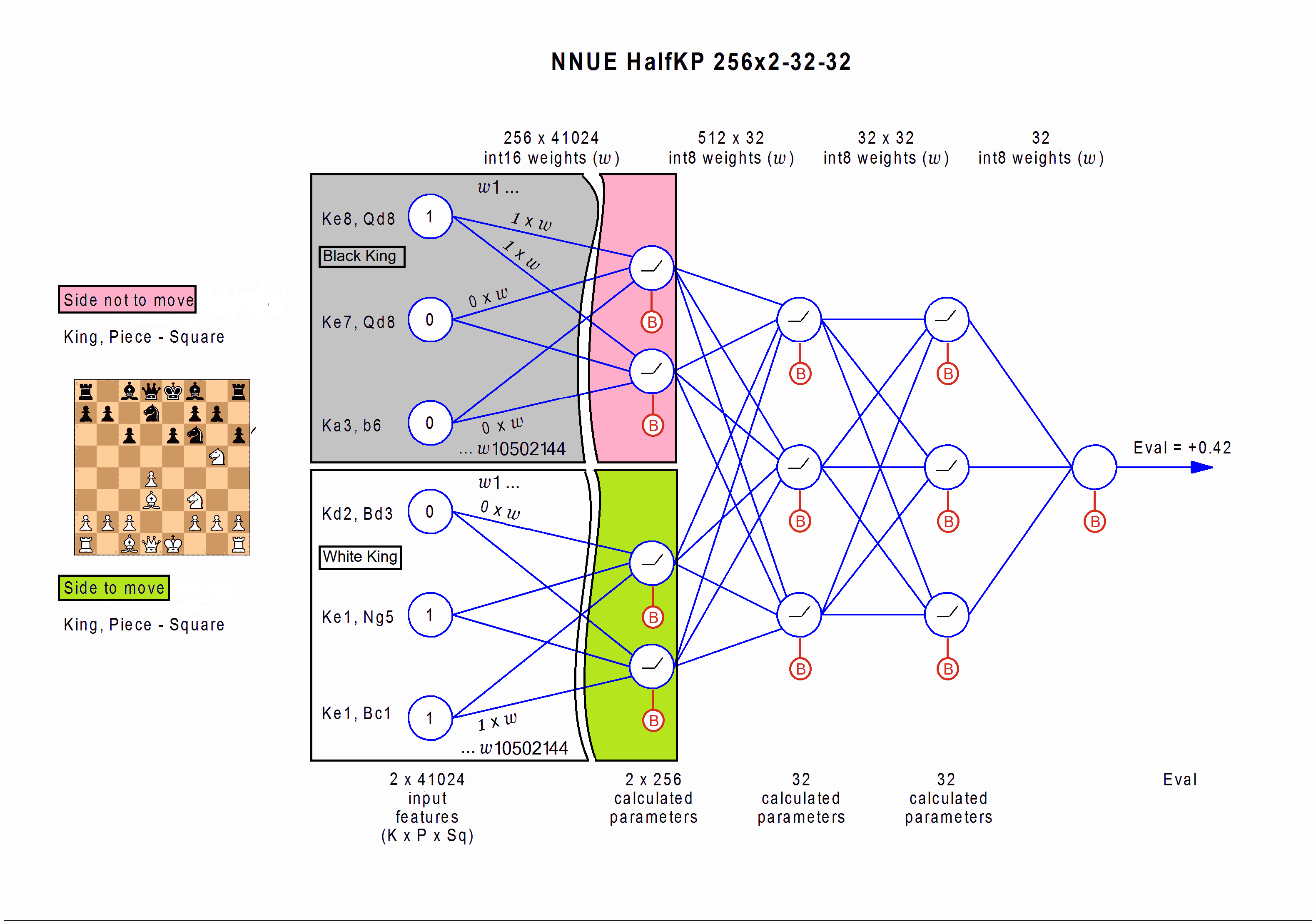
Первоначально архитектура шахматной нейросети NNUE, заимствованная из сеги, выглядела так, как показано на изображении ниже.
Такая нейросеть имеет достаточно простую структуру. Она состоит всего из четырех полносвязных слоев, три из которых очень невелики. На вход сети слева подается позиция, которую требуется оценить, и после преобразований на каждом слое на выходе справа мы получаем ее оценку, которую можно использовать в программе.
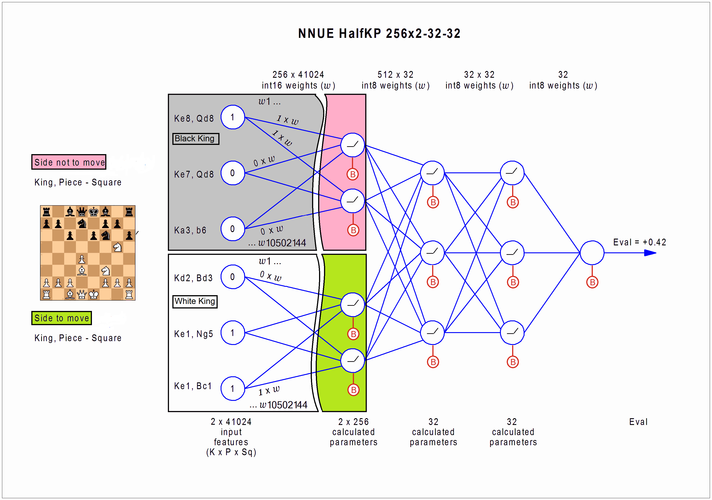
На схеме вход нейросети изображен в виде круглых ячеек слева. В них заносится позиция, сообразно с расположением фигур на доске. Упрощенно говоря, единицы соответствуют наличию, а нули отсутствию фигур по соответствующим координатам.
Далее единицы и нули со входа перемножаются на линиях на коэффициенты (веса) нейросети, а результаты суммируются по сходящимся направлениям во втором столбце ячеек. Каждой линии соответствует одно число нейросети. Таким образом из 80 тысяч ячеек с закодированной позицией слева мы получаем группу вычисленных параметров в 512 ячейках справа. Соединяющая их группа линий представляет собой входной слой нейросети.
После небольшого преобразования чисел во втором столбце ячеек, мы аналогичным образом производим вычисления на линиях следующего слоя нейросети и на выходе из него получаем 32 числа в третьем столбце ячеек (из 512 во втором). Этот слой называется первым скрытым слоем.
Аналогичным образом производятся вычисления во втором скрытом слое - из 32 чисел в третьем столбце мы получаем 32 числа в четвертом.
На выходном (четвертом по счету) слое все 32 числа аналогичным образом сводятся в единую оценку. На схеме она обозначена круглой ячейкой справа. После небольшого преобразования этого числа мы получаем "готовую к употреблению" оценку позиции. Эта оценка идет в дерево перебора, где применяется, как результат вычислений функции оценки позиции - evaluate(pos). О том, каким образом она используется в процессе поиска по дереву вариантов, рассказывается в предыдущих и следующих частях статьи.
 |
|
|
| номер сообщения: 54-72-8260 |
|
|
|
|
*****
Успеху NNUE способствовала очень тщательная адаптация к архитектуре современных CPU. Для того чтобы подобные сети работали быстро требуется использовать специальные технические решения. NNUE "играет" на некоторых нюансах в отношении тонкостей кодирования и преобразования данных, которые предоставляют значительные преимущества и экономят вычислительные ресурсы для данной архитектуры.
Большая часть оптимизаций NNUE сосредоточена на входном слое. Давайте на базе приведенной выше схемы рассмотрим подробнее, как они приносят выгоду нейросети такого формата.
В нейросеть архитектуры NNUE позиция подается на вход (на схеме с левой стороны) не так, как это обычно принято. В отличие от записи позиции стандартной строкой FEN, здесь напротив ценится не компактность, а разреженность.
Ячейки на входе, в которые заносится позиция, представлены для всех возможных сочетаний координат и типов фигур. В упрощенном представлении, для каждого из шести типов фигур двух цветов существует по 64 возможных расстановки на доске. То есть, для всех возможных положений фигур всего будет 2х6х64 = 768 ячеек. Единица в каждой из них будет свидетельствовать, что данная фигура находиться на данном поле, а ноль, что отсутствует.
В реальной сети NNUE идут еще дальше. Здесь ячейки свидетельствует о наличии по определенным координатам двух фигур - короля одного из цветов и какой-то другой фигуры, любого цвета. То есть каждая ячейка является "именной" и привязана к определенной координате и типу фигур. Таким образом, когда на входе позиция заносится в ячейки, всего доступно (2х64) х (5х2х64) = 80 000 ячеек - для двух королей, при 64-х возможных координат позиции короля на доске, и 5 типов других фигур, черных и белых, с 64 возможными положениями на доске каждой.
В ячейку проставляется единица, только если обе фигуры находятся на координатах ячейки. Например (см. на схеме) если в позиции черный король находится на поле e8, а ферзь на поле d8, то в ячейке будет единица, а все ячейки для иных их расположений, где хотя бы одна из фигур отсутствует, заполняются нулями. Такое бинарное (0 или 1) представление позиции на входных ячейках имеет свои преимущества, о чем будет рассказано ниже.
На входном слое расчеты производятся по двум путям. Каждый из них вычисляется раздельно - один путь предназначен для связей черного короля относительно других фигур любого цвета (на схеме он расположен выше), а второй путь аналогично вычисляется для белого короля.
Понятно, что в большинстве входных ячеек находятся нули, поскольку либо одна, либо вторая фигура по координатам ячейки отсутствуют. Король и фигура находятся вместе для каждого возможного сочетания координат в очень редких случаях. По факту заполняются единицами максимум 2х30 входных ячеек - это наиболее возможное количество фигур на доске по обоим путям, за вычетом королей. Таким образом, количество "единичных" сочетаний король-фигура будет равно количеству фигур на доске.
Соответственно, при таком способе ввода позиции, подавляющее большинство связей (линий) на входном слое не используются, так как на них должны происходить перемножения на ноль, с очевидным итогом. Поскольку конечный результат таких "умножений" заведомо нулевой, то к сумме результатов во втором столбце ячеек они ничего не добавят. Поэтому такие входные ячейки вычисляться не будут.
У подобного разреженного представления есть свои преимущества. Для каждой вводимой позиции единицы и нули будут в разных ячейках, то есть всякий раз для вычислений будет использоваться свое уникальное сочетание активных ячеек, отличное от других позиций и соответственно свое сочетание используемых коэффициентов. Таким образом, любая позиция на входном слое будет вычисляться по собственному пути.
Получается, сеть сильно сэкономит вычислительные ресурсы и в то же время у каждой позиции будет свой оригинальный набор вычисляемых параметров. Это обеспечит, в некотором смысле, разную "нейросеть" на входном слое для каждой позиции. Имея 80 000 входных условий, сеть может гибко подстроиться под каждую позицию, оперативно адаптируя, таким образом, свою "базу знаний". |
|
|
| номер сообщения: 54-72-8261 |
|
|
|
|
Избыточное количество знаний (коэффициентов) позволяет отчасти компенсировать малое количество вычислений, которое критично для относительно слабосильных, в сравнении с видеокартами, векторов центральных процессоров.
Кроме всего прочего, используя связки король-фигура, мы как бы "подсказываем" нейросети важные сочетания фигур, которые сеть вследствие своей небольшой глубины не успевает/не имеет возможности вычислить самостоятельно. В каком-то смысле здесь мы заранее "вычислили" для нее важные признаки позиции.
Такое представление позиции называется оверпараметризированным. По сути избыточным для крупных нейросетей, но выгодным для архитектуры NNUE. Можно сказать, что NNUE работает по принципу энциклопедии. Содержит большой объем информации (коэффициентов), но использует только небольшую ее часть для получения оценки позиции в каждом отдельном случае.
На каждой линии выходящей из входной ячейки находится один множитель/коэффициент нейросети, поэтому всего существует 10 млн. коэффициентов или 2х40000х256 = 20 млн. возможных вычислений (верхний и нижний путь используют одинаковые коэффициенты). В то же время, реальное количество вычислений для подаваемой на вход позиции на "линиях" входного слоя нейросети не превысит 2х30х256 = 15 000 умножений и столько же сложений полученных результатов. Конечно, при сокращении количества фигур на доске в процессе игры, количество "единиц" и соответственно вычислений станет еще меньше.
По большому счету, на входном слое не обязательно производить любые умножения. Задавая на входе позицию лишь нулями и единицами, можно избежать операции умножения на 1, поскольку она ничего не даст кроме самого числа. Соответственно на входном слое можно выполнять лишь операции суммирования в ячейки второго столбца по сходящимся линиям от "единичных" коэффициентов нейросети.
Еще одна оптимизация заключается в том, что когда перебор скользит по дереву вверх-вниз, производя и откатывая ходы, то при каждом отдельном ходе меняется лишь положение одной фигуры. Для остальных фигур активные ячейки останутся прежними, а значит и вычисляемые значения будут те же самые. В таком случае можно сохранить вычисления предыдущей позиции и лишь прибавить-вычесть пару значений во всех ячейках второго столбца для ходившей фигуры. Поэтому если только не ходил король, начинать расчет с нуля не обязательно.
То есть нужно из сумм в ячейках второго столбца (аккумулятора) вычесть веса предыдущего положения фигуры и прибавить веса ее нового положения. В некоторых случаях, например при взятиях, придется еще удалить значения по линиям от снятой фигуры, так как в ее ячейке теперь ноль. И только при движении короля изменится положение каждой "единичной" связи, поэтому придется пересчитать все суммы, но только по одному пути, то есть 30х256 коэффициентов.
Это основные оптимизации на входном слое, делающие архитектуру NNUE такой удачной, при ее в общем-то небольшом размере и простоте.
В конечном итоге, сохраняя в некотором отношении гибкость большой нейросети, NNUE имеет объем вычислений в тысячи раз меньше. Разумеется не без последствий, но тем не менее со своей выгодой. |
|
|
| номер сообщения: 54-72-8262 |
|
|
|
|

*****
Давайте перейдем к более предметному описанию нейросети NNUE в том виде, в котором она была первоначально реализована в Стокфише.
За входной слой отвечает Feature Transformer. С приложением всех оптимизаций, вычисления на нем сводятся к простому суммированию во второй столбец ячеек (accumulator) "активированных" весов сети (weights), т.е. весов с линий из ячеек с единицами (features).
Как уже отмечалось выше, такие вычисления можно проводить двумя способами - полное (refresh), с пересчетом для всех активных линий или частичное (update), только для изменившей свое положение фигуры. Во втором случае используются сохраненные ранее состояния аккумулятора из стека предыдущих позиций. Примерный код реализации можно посмотреть здесь:
https://github.com/official-stockfish/nnue-pytorch/blob/master/docs/nnue.md#feature-transformer-2
Полученные значения во всех ячейках складываются с еще одним отдельным числом для каждой ячейки (Bias). Если итоговый результат в ячейке выходит за пределы допустимого диапазона значений, то есть итог вычислений перейдет через верхний или нижний предел, то он "подрезается" до ближайшего разрешенного значения с помощью Clipped ReLU.
Далее вектор во втором столбце ячеек из 256 чисел белого короля, и аналогичный вектор из 256 чисел для черного, стыкуются в единый вектор из 512 чисел в порядке очереди хода (с каждым ходом обе части меняются местами). Попутно производится преобразование (quantisation) целых чисел входного слоя из 16-битного формата int16 к более простому 8-битному представлению int8. Он будет использоваться для остальных слоев.
Таким образом, на входном слое вычисления производятся над 16-битными целыми числами. На других слоях можно использовать меньшую точность, поэтому размерность чисел снижают до 8 бит с помощью квантизации. Это еще одна оптимизация, среди прочих.
Далее вычисления подхватывает первый скрытый слой (Linear layer 1). Входной вектор из 512-ти чисел для этого слоя (второй столбец ячеек на схеме) перемножают на матрицу первого скрытого слоя нейросети (таблица чисел) с помощью аффинного преобразования. Оно заключается в ротации (повороте) блоков чисел для более удобного вычисления и позволяет быстро и эффективно выполнять умножение вектора на матрицу, то есть перемножать строки чисел на столбцы таблицы чисел.
https://github.com/official-stockfish/nnue-pytorch/blob/master/docs/nnue.md#linear-layer-4
Аналогично, на выходе слоя к суммам в ячейках добавляют bias и производится обрезка полученных значений с помощью Clipped ReLU.
https://github.com/official-stockfish/nnue-pytorch/blob/master/docs/nnue.md#clippedrelu-2
Пройдя по всем оставшимся слоям подобным образом, мы получаем оценку позиции.
https://github.com/official-stockfish/nnue-pytorch/blob/master/docs/nnue.md#putting-it-together
В целом, большинство из оптимизаций входного слоя не применимы на скрытых слоях. Поэтому объем вычислений на них мог бы многократно возрасти. Чтобы удержать его в разумных пределах размерность таких слоев приходится сильно уменьшать. Сокращение числа вычисляемых параметров необходимо еще потому, что вычислительные мощности векторных блоков процессоров гораздо скромнее, чем у тензорных ядер видеокарт. А перемножать приходится в полносвязных сетях, что дополнительно увеличивает объем вычислений.
На первом скрытом слое количество вычисляемых параметров уменьшается с 512-ти до всего 32-х чисел. На втором скрытом слое их количество остается таким же небольшим.
Соответственно, на первом скрытом слое производится 512 х 32 = 16 384 умножений чисел и затем столько же сложений полученных результатов. Плюс указанные выше преобразования. На втором скрытом слое производится 32 х 32 = 1024 умножений и столько же сложений. Выходной слой содержит еще меньше вычислений.
Для перемножения и сложения этих чисел используются специальные блоки центральных процессоров. В отличие от тех же ALU, они перемножают сразу группы чисел, собранных в определенном порядке - так называемые вектора. Поэтому каждое перемножение пары 256-битных векторов AVX2 позволяет производить за один такт сразу 32 умножения 8-битных целых чисел. При использовании FMA в тот же единственный такт укладывается еще и сложение полученных результатов. А учитывая, что в ядре процессора содержится сразу несколько векторных блоков, то соответственно каждое ядро процессора производит за такт еще кратно больше вычислений.
В конечном итоге, наиболее вычислительно требовательными остаются входной и первый скрытый слои. Хотя входной слой содержит гораздо больше коэффициентов (весов) нейросети, он является разреженным и по объему вычислений обычно не превосходит первый скрытый слой. В свою очередь второй скрытый и выходной слои вычисляются уже гораздо быстрее. |
|
|
| номер сообщения: 54-72-8263 |
|
|
|
|
*****
Приведенная выше схема вычисления оценки позиции примерно соответствует тому виду, в котором она была перенесена в шахматную программу Стокфиш из сеги в августе 2020 года. Первый официальный релиз Стокфиша 12 с нейросетью, состоялся в сентябре и не слишком отличается от рабочих версий программы.
Исходный код для структуры нейросети, которой посвящена эта часть статьи, можно найти в папке nnue программы Стокфиш 12. В современном Стокфише 18 общая структура нейросети изрядно усложнилась. Тем не менее, базовая архитектура и общее количество слоев (то есть глубина сети), введенная когда-то в сеги, остались прежними. Это все еще полносвязная нейросеть "мелкого заложения".
Более подробный обзор ранней и современной реализации структуры нейросети NNUE, применительно к практике, можно найти на отдельной страничке Стокфиша на гитхабе. На нее уже делались отсылки выше:
https://github.com/official-stockfish/nnue-pytorch/blob/master/docs/nnue.md
В целом, с момента появления в шахматных программах, нейросети NNUE претерпели множество изменений. Часть из них были вынуждены для адаптации к реалиям шахмат, но в основном они касались увеличения размеров сети "в ширину" и усложнения ее общей структуры.
С течением времени в Стокфише было увеличено количество вычисляемых параметров (размеры) входного и первого скрытого слоя нейросети. На входе помимо информации о координатах фигур, добавлена информация о фигурах атакующих другие фигуры (угрозах). Она позволила "обратить внимание" нейросети на соответствующие важные факторы позиции.
Помимо этого, в некоторых слоях вычисления были разбиты на несколько этапов. Добавлены так же различные остаточные (residual) связи.
На выходых слоях нейросети появилось несколько путей вычислений (buckets), из которых выбирается только один, в зависимости от количества материала на доске. Такая "развилка" вычислений позволяет до некоторой степени адаптировать оценку к позициям из разных стадий партии.
Кроме исходных текстов самой программы Стокфиш 18, за подробной информацией по всем вопросам связанным с общей архитектурой, получением данных для обучения и режимах тренировки сети следует обращаться к wiki Стокфиша на гитхабе. Здесь все расписано гораздо подробнее и применительно к реальной программе, в том числе по всем темам, которых мы лишь кратко касались выше.
https://github.com/official-stockfish/nnue-pytorch/wiki
На этом мы закончим общий обзор типов оценочных функций, применяемых в шахматных программах на классической базе. В следующей части вернемся обратно к перебору и рассмотрим исходный код поиска шахматной программы Стокфиш. Кому не интересны вопросы непосредственной реализации логики перебора на примерах кода, могут сразу перейти к заключению в последней части статьи.
Продолжение следует... |
|
|
| номер сообщения: 54-72-8264 |
|
|
|
|
Тут вообще интересно то, что, технически говоря, сеть сама "должна бы знать", какие фигуры друг друга атакуют и т.д. Ведь это легко считается из правил шахмат и их расположения.
Но на практике выясняется, что это не так, и информация об атаках фигур друг на друга, сгенерированная руками, работает лучше. |
|
|
| номер сообщения: 54-72-8265 |
|
|
|
|
| Все же, очень уж мелкая сеть, не успевает она. Всего четыре слоя, и те смех один. Поэтому не удивительно, что некоторые моменты пришлось отдельно подчеркнуть прямо на входе. |
|
|
| номер сообщения: 54-72-8266 |
|
|
|
|
Ну я бы сказал, что это скорее принципиальное ограничение нейросетей.
Если у задачи есть правильное и строгое решение, то нейросети могут к нему приблизиться, но его не достигают. |
|
|
| номер сообщения: 54-72-8267 |
|
|
|
|
Нейросеть стремится аппроксимировать 32-х фигурную таблицу "окончаний". То есть правильное и строгое решение. Но это в общем-то, несколько иной вопрос.
Но в некотором отношении все же могу согласиться. Даже глубокой нейросети Альфа-Зеро давали на входе избыточную информацию в виде нескольких предыдущих позиций, чтобы она могла отчасти понимать динамику. |
|
|
| номер сообщения: 54-72-8268 |
|
|
|
|
| Насколько я помню, Threat inputs впервые появились в Monty. |
|
|
| номер сообщения: 54-72-8269 |
|
|
|
|
Шахматные программы VI. Структура поиска Stockfish
В этой части мы наконец-то обратимся к коду реальных программ. Примером нам будет служить код поиска шахматной программы Стокфиш. В настоящее время это безусловно сильнейшая шахматная программа в мире.

Начиная с этой части, мне придется обратиться к области, которую я не знаю в достаточной степени. Все-таки, не будучи программистом обсуждать код программ довольно рискованно. Но по-видимому без этого не обойтись. Все описания выше должны быть проиллюстрированы текстами какой-либо сильной программы.
Начать наверное стоит с пояснения - то что обычно называется шахматной программой, или иначе "движком", на самом деле запускается из консоли. К пользователю программа обращается через графическую оболочку - GUI. Графическая оболочка сама по себе в шахматы не играет. Она только отрисовывает доску и отображает ходы, которые посылает ей движок. Также она предоставляет всевозможные сервисные функции, запускает различные виды анализа, позволяет работать с базами партий. Через нее подключаются дебютные книги и наборы стартовых позиций, эндшпильные базы и т. д. Ссылка на страницу с описанием популярных графических оболочек была дана в конце IV части.
Оболочка общается с движком через UCI-протокол. Это набор стандартизованных команд, который понимают обе программы. Сейчас UCI это общепринятый стандарт шахматных протоколов, хотя существуют и другие, например WinBoard. Одна оболочка может руководить не одним движком, а запустить, например, несколько шахматных программ одновременно для анализа, устраивать между ними турниры и т. д.
Краткий гайд по основным командам UCI и настройкам Стокфиша можно найти здесь:
https://github.com/official-stockfish/Stockfish/wiki/UCI-&-Commands
https://drive.google.com/file/d/1_1Vd52xvGOJYPs1y_f15lGlkauErOR02/view
Исходные тексты программы Стокфиш можно найти на ее официальной страничке на гитхабе. Не так давно вышла 18-я версия этого движка. На ее код мы и будем ориентироваться:
https://github.com/official-stockfish/Stockfish/tree/cb3d4ee9b47d0c5aae855b12379378ea1439675c
В данном обзоре мы будем в основном рассматривать поиск по дереву вариантов, т.е. перебор. Поэтому файл с которым придется работать это search.cpp. К нему мы будем обращаться по умолчанию.
Код поиска, это основа с которой стартует содержательная часть программы. Фактически можно сказать, что отсюда стартует сама шахматная программа.
Здесь запускаются все виды перебора. Отсюда идет обращение к оценочной функции и другим частям кода. Когда поиск (search) заканчивает перебор, достигая заданной глубины (depth уменьшается до 0), а затем проведет форсированный перебор, он обращается к оценочной функции в файле evaluate.cpp, из под которого уже идет обращение к нейросети. Весь связанный с нейросетью код храниться в папке nnue. |
|
|
| номер сообщения: 54-72-8270 |
|
|
|
|
*****
Но прежде, чем мы перейдем непосредственно к структуре программы, необходимо коснутся использования термина глубины (depth) в шахматных программах. В движках обычно используется несколько параметров для ее отсчета. Эти параметры используются для разных целей и нередко возникают проблемы с пониманием их работы.
В первую очередь, глубина может отсчитываться как бы с разной стороны дерева. При текущем переборе определенной ветки, параметр глубины (depth) отсчитывается в сторону уменьшения от параметра заданного функцией перебора (search). При depth = 0 по условию включается Quiescence Search (см. окончание части I). Таким образом, глубина считается как бы в обратную сторону - максимальное значение у нее в "корне" функции, и далее она уменьшается в направлении конца ветки. Таким образом, говоря о "углублении" в дерево перебора, мы можем быть немного дезориентированы уменьшением при этом параметра depth.
В свою очередь есть параметры глубины, которые используются более интуитивно - с возрастанием от корня к конечным (их еще называют листовыми, листьями) позициям. Так, например в Стокфише есть такой параметр как rootDepth, который используется при запуске итеративного цикла из корня. Есть еще selDepth, который учитывает глубину продлений вдобавок к итеративной, а также ply - они в общем-то похожи, у них только немного разная точка отсчета.

*****
Поиск Стокфиша можно рассматривать как некий каскад из четырех частей - функций. Перебор начинается с запуска функции start_searching. В процессе исполнения она запускает функцию итеративного углубления (iterative_deepening). Та запускает основную функцию поиска (search), из которой в свою очередь поиск продляется форсированными вариантами (функция qsearch). Все функции находятся в файле search.cpp. Рассмотрим их по порядку.
1. Начало перебора
Графическая оболочка сначала инициализирует движок, отправляя ему команду uci, а следом шлет настройки, которые выставил пользователь.
Старт общего перебора запускается из строки:
183 start_searching()
Здесь производится запуск главного и всех остальных потоков, раздача заданий каждому из них, сравнение результатов и их останов. То есть под данным заголовком по большей части идет распараллеливание.
Первым стартует основной поток (Main thread) и он уже запускает остальные. Все потоки запускаются в количестве указанном в настройках. Под start_searching в файле search.cpp находятся только команды вызова функций. Сами функции можно посмотреть в файлах thread.
Потоки запускаются сначала на холостом ходу (idle_loop), не производя никакой работы и не загружая процессор. Только когда движок получает от оболочки команду go, вместе с текстом партии или позицией, потоки выходят из спящего режима и начинается перебор вариантов через функцию start_thinking (не путать со start_searching).
Потоки практически независимы друг от друга и оперативно обмениваются результатами через хеш-таблицы, общие для всех потоков. Использование общих хеш-таблиц не только помогает потокам выбирать лучший ход пользуясь результатами параллельных поисков, но также уменьшает дублирование перебора, хотя и не в полной мере. Почти все остальные таблицы, и в первую очередь таблицы истории, у каждого потока свои. То есть за исключением хеш-таблиц, в каждом потоке таблицы с разными данными. Это ключевой источник вариативности перебора.
Несинхронизированная запись потоками в хеш-таблицы позволяет делать поиск недетерминированным. Накапливающиеся расхождения записей в таблицах истории у потоков приводят к различию их деревьев перебора, что в свою очередь позволяет находить "потерянные" варианты отдельными потоками. Иначе говоря, хеш-таблицы обеспечивают обмен информацией между потоками, а таблицы истории обеспечивают вариативность. Это изрядно усиливает перебор и эффективно масштабирует его на любое количество ядер процессора.
С недавнего времени у Стокфиша стали общими не только хеш-таблицы, но и некоторые другие. Ниже по тексту мы еще вернемся к вопросам распараллеливания.
Точек синхронизации у потоков нет. По окончании перебора производится "голосование" за лучший поток:
237 bestThread = threads.get_best_thread()->worker.get()
Из под start_searching запускается функция перебора каждого из потоков по отдельности:
190 iterative_deepening() |
|
|
| номер сообщения: 54-72-8271 |
|
|
|
|
2. Итеративное углубление
Функция итеративного углубления запускает перебор на каждом потоке со строки:
259 iterative_deepening()
Это старт перебора одного потока. Итеративный цикл запускается со строки:
322 while (++rootDepth < MAX_PLY && !threads.stop
&& !(limits.depth && mainThread && rootDepth > limits.depth))
Функция запускается в корневой позиции и увеличивает глубину rootDepth на один полуход за цикл, до тех пор, пока не достигнет конечного значения. Но чаще всего прерывание вызывается окончанием времени, выделенного на ход. Выделяемое время гибко регулируется с помощью специальных правил, отталкиваясь от заданного пользователем в оболочке "тарифного плана". Возможен также перебор на фиксированную глубину.
В начале перебора из корня производится спекулятивный выбор размера альфа-бета окна с помощью метода Aspiration windows (см. IV часть). При выходе функции search за пределы спекулятивных границ, значение оценки признается недостоверным (хотя и отображается на экране). После этого границы определяемые значениями альфы и беты немного расширяются или сдвигаются и производится повторный перебор на ту же глубину. До тех пор пока происходит выход за границы, цикл/перебор повторяется. Если количество повторов становится чрезмерным, глубина может быть даже временно снижена.
Многократно фигурирующий в функции параметр MultiPV - это запуск перебора в несколько линий. В целом он ослабляет программу и нужен для ручного анализа или запуска в режиме уменьшения силы игры. В полноценной партии для выбора хода он не используется. По умолчанию будем считать его всегда равным единице.
Под каждым циклом итеративного углубления запускается перебор на заданную глубину вызовом функции search:
375 bestValue = search< Root>(rootPos, ss, alpha, beta, adjustedDepth, false)
3. Основной перебор
В каждом цикле итеративного перебора запускается функция перебора на заданную глубину со строки:
615 search(Position& pos, Stack* ss, Value alpha, Value beta, Depth depth, bool cutNode)
search - это основная функция поиска. Альфа и омега всего перебора. Источник силы всей программы. Если собираетесь проникнуть в самую ее суть, то обращайтесь сюда. В первую очередь к шагам (Step) с 7-го по 20-й, где сосредоточена основная логика выбора направления перебора - продлений, сокращений, отсечений и всего остального, о чем мы говорили во II части.
Эта функция слишком большая, чтобы ограничиться ее кратким обзором. Мы посвятим ей целиком следующую часть статьи.
Как только перебор функции search по какой-либо из веток достигает заданной глубины, то запускается форсированный вариант поиска:
622 // Dive into quiescence search when the depth reaches zero
623 if (depth < = 0)
624 return qsearch< PvNode ? PV : NonPV>(pos, ss, alpha, beta);
|
|
|
|
| номер сообщения: 54-72-8272 |
|
|
|
|
4. Форсированный перебор
Когда основной перебор в какой-либо ветке достигает определенной (заданной) глубины (depth = 0), он запускает перебор форсированных ходов - Quiescence Search:
1496 qsearch(Position& pos, Stack* ss, Value alpha, Value beta)
Далее в глубь допускается смотреть только взятия и отчасти шахи. Обоснование необходимости метода смотрите в концовке I части статьи.
Quiescence Search во многом похож на упрощенную версию основного поиска. Он повторяет многие методы, но расчет идет не до заданной глубины, а до исчерпания разменов. Есть в QS и оригинальные методы отсечений. Например, так называемый Stand pat:
1581 else
1582 {
1583 unadjustedStaticEval = evaluate(pos);
1584 ss->staticEval = bestValue =
1585 to_corrected_static_eval(unadjustedStaticEval, correctionValue);
1586 }
1588 // Stand pat. Return immediately if static value is at least beta
1589 if (bestValue >= beta)
1590 {
1591 if (!is_decisive(bestValue))
1592 bestValue = (bestValue + beta) / 2;
... ...
1598 return bestValue;
1599 }
1601 if (bestValue > alpha)
1602 alpha = bestValue; |
Здесь мы сначала вычисляем статическую оценку позиции и если она выше беты, то не считаем размены, а сразу производим отсечение и выходим из QS. Таким образом на ветке можно сберечь некоторое количество ресурсов компьютера, не считая бесполезные взятия.
Идея в том, что если бы даже с последующими разменами оценка и опустилась ниже беты, то мы можем отказаться от разменов, так как в шахматах рубка не обязательна, и выбрать тихий ход. Кроме того, поскольку оценка в позиции рассматривается с точки зрения стороны, чей сейчас ход, то этот ход почти наверняка не опустит нам оценку. Поэтому оценка должна превысить бету и отсечение состоится.
5. Оценка позиции
Когда и в Quiescence Search достигается предельная глубина, то есть окончание разменов, запускается определение оценки позиции, например из строки:
1583 evaluate(pos)
Это так называемая статическая оценка позиции, вычисляемая на основании только количества и взаимного расположения фигур на доске, без их передвижения. Здесь происходит обращение к файлу evaluate.cpp. Из него идет выход на оценочную функцию в виде нейросети через папку nnue.
Нейросетей используется две - основная и крошечная вспомогательная. Вспомогательная сеть предназначена для частных случаев с большой оценкой - такие позиции обычно не требуют качественной оценки, их выгоднее оценивать побыстрее.
(P.S. Совсем недавно малая вспомогательная сеть была все же удалена из Стокфиша.) |
|
|
| номер сообщения: 54-72-8273 |
|
|
|
|
*****
Под конец хотелось бы еще раз коснуться вопросов распараллеливания. В настоящее время, когда количество ядер у центральных процессоров растет опережающими темпами, эта тема становится особенно актуальной.
Современные шахматные программы на классической базе используют для расчетов только мощности CPU, в том числе вектора для расчета матриц нейросетей. Видеокарты (GPU) для вычисления нейросеток не получается задействовать из-за очень большой задержки по передаче данных туда-обратно, что понизило бы скорость перебора в тысячи раз.

Напротив, для огромных сетей Лилы (Leela Chess Zero, Lc0) и прочих программ, созданных на базе Альфа Зеро, этот вопрос не актуален, поскольку у них скорость и так невелика. Но у таких программ тоже есть свои проблемы. Здесь в свою очередь простаивает центральный процессор, так как у него не очень много работы, вследствие того, что большие нейросетки требуют много времени на вычисления даже на видеокартах. А MCTS последовательный процесс, который должен получить с видеокарты оценки для предыдущего пакета позиций, прежде чем апгрейдить дерево перебора и собрать новый пакет.
Вопрос распараллеливания шахматных программ поднимался еще очень давно. Уже в конце 70-х пытались наладить работу программ на нескольких машинах вместе. Но долгое время он представлял больше академический интерес, за редким исключением в виде программ для Крей Блиц, Дип Блю и некоторых иных машин. Но с постепенным распространением многоядерных машин, проникновением их на потребительский рынок шахматных программ в начале 00-х, вопрос все больше переходил в практическую плоскость. В современном мире, когда количество ядер на процессорах все время растет - и часто это чуть ли не единственная метрика прогресса машин, тема распараллеливания стала такой же важной, как и прочие методы совершенствования шахматных программ.
Проблема с самого начала стояла исключительно остро, поскольку базовый метод обхода дерева на основе альфа-бета отсечений имеет последовательную природу. Выбор каждой следующей ветки для рассмотрения перебором, это результат отсечения (или не отсечения) предыдущей - куда направится перебор предсказать заранее нельзя.
При всем разнообразии изначальных схем распараллеливания, основная мысль повернула в направлении раздавать параллельным процессорам/ядрам/потокам те ветки дерева, которые будут вычисляться в любом случае. Примерно к концу 00-х на первое место по популярности вышел метод YBWC. Лежащий в его основе принцип распараллеливания заключался в том, что если первым ходом по сортировке отсечения не произошло, то и дальше его скорее всего не произойдет и остальные ходы по сортировке раздаются всем свободным потокам.
Очевидно, что большинство таких вариантов будут раздаваться из All-nodes. Предполагалось, что на подветках таких вариантов найдется работа для всех потоков. Но как оказалось, на системах с более чем 16 ядрами, потоки большей частью простаивали ожидая новых заданий и положительный эффект от распараллеливания сводился практически к нулю.
Если же делать потоки более независимыми, то "поднимает голову" избыточный перебор, то есть повторный перебор одних тех же веток несколькими потоками, или же напрасный перебор одними потоками веток, уже отсеченными другими потоками.
Более продвинутым с точки зрения эффективной загрузки потоков в те годы считался метод DTS, но он был настолько сложен в реализации, что его мало кто использовал. Со все большим распространением систем ПК с двузначным числом ядер, вопрос распараллеливания снова подвис в воздухе. |
|
|
| номер сообщения: 54-72-8274 |
|
|
|
|
К счастью, около 2014 года был найден метод, который разрешил все проблемы. Он получил название LazySMP, но по сути оказался реинкарнацией старых методов с общим хешем.
Идея была известна уже давно. Нужно было пустить все потоки в "свободное плавание", сделав их абсолютно независимыми, без процессов синхронизации, а обмениваться информацией они должны только через общую для всех потоков хеш-таблицу. Все остальные таблицы (в первую очередь History) будут свои для каждого потока, и вследствие общей недетерминированности расчетов на каждом потоке, создадут естественную вариативность. Желательно было только принять дополнительные меры, чтобы потоки еще больше расходились по разным веткам естественным путем.
Но все равно получалось так, что избыточный - суть повторный перебор, у разных потоков зашкаливал. Поэтому ранее на системах с более чем двумя потоками такие методы эффективно не работали. А сейчас вдруг заработали…
Неожиданно системы с десятками и даже сотнями ядер стали увеличивать силу игры кратно их числу. По эффективности прибавки кратное увеличение числа ядер стало приближаться к эффективности аналогичного увеличения времени на обдумывание. Ясно было, что закон Амдала, накладывающий ограничения на эффективность параллельных систем удалось как-то обойти. Но как?
Достаточно быстро пришло понимание, что виной тому отсечения с потерями. Отсечения на побочных ветках имеют тот эффект, что часть важных ходов теряется. Очень селективный современный перебор иногда слишком уж отсекает побочные ветки, пусть и с положительным общим эффектом для силы движка. В свою очередь "расширяя" перебор, иногда можно их найти.
Даже при большой надежности методов отсечения, "поле" отсекаемых ходов слишком велико и количество преждевременно отсеченных вариантов в совокупности должно быть очень большим. В свою очередь в шахматах одна-две серьезные ошибки обычно решают партию. Поэтому отыскание таких "потерянных PV" является важным элементом шахматного поиска. Отсюда следует, что нахождение даже небольшого количества этих ходов может с лихвой скомпенсировать и солидные потери на распараллеливание, выраженные избыточным перебором.
Раньше, когда преимущественно использовались отсечения альфа-бетой, которая как известно отсекает без потерь, методы с общим хешем естественно не могли быть эффективными, так как искать на этом "поле" отсеченных вариантов было нечего.
Пока что описания конкретных механизмов отыскания ходов-кандидатов в преждевременно отсеченных ветках мне встречать не приходилось. Рискну взять на себя такую ответственность и предложить один из возможных вариантов. Но конечно все рассуждения ниже еще требуют своего подтверждения.
Начнем с того, что при обходе дерева, ошибки перебора обычно случаются, если тот не может досчитаться до глубины достаточной, чтобы увидеть последствия своих действий. То есть его вариантам недостает глубины. Если бы перебор мог просчитать все ветки дерева до конца партии, до конечного ее результата (их всего три - победа, ничья или поражение), то он бы не допускал ошибок и всегда выбирал бы лучший ход. Но поскольку дерево шахмат слишком велико, то часть веток приходится сокращать.
Таким образом - пусть эта граница и достаточно размыта, ветви перебора можно разделить на два вида. Одни из них, это варианты близкие к основному. Они считаются на полную (заданную) или почти полную глубину. Им может недоставать глубины из-за недостатка времени и скорости железа.
На побочных ветках основной ограничитель глубины, это отсечения и сокращения. От времени на обдумывание и скорости такие ветки получают гораздо меньше пользы, поскольку их глубина растет кратно медленнее. Следовательно, им нужны другие источники усиления.
Более селективный перебор, в понимании "сужения" дерева в результате отсечений, помогает увеличить глубину основных вариантов. Напротив, на пользу побочным вариантам идет "расширение" перебора, но это ослабляет программу в целом. Получается "конфликт интересов" обоих способов. Исторически, перебор почти всегда улучшался увеличением его селективности путем "сужения" дерева.
Старые методы распараллеливания перебора в основном помогали уменьшить время набора глубины, то есть помогали в первую очередь основным, а не побочным веткам. Современный метод распараллеливания LazySMP, тоже отчасти позволяет ускорить основной перебор через общую хеш-таблицу, но главная польза от него происходит на побочных вариантах. LazySMP помогает находить на таких ветках ходы-кандидаты в преждевременно отсеченных вариантах.
Как указано выше, таблицы истории (Histоry) у каждого потока свои. Вследствие естественной недетерминированности и отсутствия синхронизации потоков эти таблицы могут заполняться по разному на разных потоках. Значит одни и те же ходы в одних и тех же позициях на каждом потоке могут исследоваться на различную глубину, вследствие вариативности происходящей от сортировки для LMR каждого потока.
Как следует из эффективности тех же киллеров, на одной ветке может произойти сразу целая серия отсечений в группе похожих позиций и какие-то ходы могут резко подняться в таблице истории у отдельного потока. Отсюда, на этом потоке они будут исследоваться по LMR на гораздо большую глубину, чем на остальных. Значит такие продолжения получат более пристальное внимание, могут поднять альфу, а впоследствии еще и пройти верификацию повторным перебором уже на полную глубину. И тогда мы получим "потерянную альфу" - по сути ход-кандидат и в перспективе "потерянный основной вариант" для этого потока, а позже и для всех остальных. Таким образом, без слишком большого избыточного перебора и расширения дерева, из побочных ветвей могут извлекаться преждевременно отсеченные варианты, которые в состоянии перевернуть оценку.
*****
На этом прервемся. В следующей части мы подробно рассмотрим основной перебор, вызываемый функцией search.
Продолжение следует... |
|
|
| номер сообщения: 54-72-8275 |
|
|
|
|
Вообще LazySMP это очень изящный способ обойти закон Амдала, выйдя за его определение. Так как закон Амдала предполагает вычисление с тем же результатом, что и без распараллеливания, то он работает на YBWC, который этим и занимается.
А т.к. результат LazySMP в целом не обязан совершенно совпадать с тем, что получается при поиске на одном потоке, но и закон Амдала тут не действует. |
|
|
| номер сообщения: 54-72-8278 |
|
|
|
|
Да, интересная вещь.
Кстати, LazySMP ведь совсем не запрещает суперлинейность при распараллеливании. Мы привыкли, что удвоение времени всегда дает больше, чем удвоение ядер, но в текущих условиях почему бы и не наоборот. В принципе ничего не мешает. |
|
|
| номер сообщения: 54-72-8279 |
|
|
|
|
Ну пока что мы даже линейности не добились вроде как.
При этом самое забавное то, что сейчас множество историй "сливается" между потоками наоборот, ну те же истории коррекции статической оценки, история пешечной структуры, а вот недавно даже continuation history. |
|
|
| номер сообщения: 54-72-8280 |
|
|
|
|
Этим историям наверное объединение и помощь от других потоков приносит больше выгоды, чем вариативность от их разделения. Сейчас разных History много стало, некоторые можно и обобщить.
Кроме того, насколько я знаю, и те истории что входят в группу sharedHistory объединяются только в пределах 32-х или 64-х потоков. По техническим причинам.
Забыл еще написать в статье, что позиции из таблиц перестановок заносятся в историю с иным весом, чем те, что программа нашла самостоятельно. Что тоже добавляет вариативности. |
|
|
| номер сообщения: 54-72-8282 |
|
|
|
|
Там же идея ещё в том, что истории статической оценки делаются по хэш-сумме позиционного параметра (например, пешечной структуры). Разумеется, т.к. пешечных структур возможных огромное количество, непосредственно её целиком записать не выйдет, поэтому используется хеширование в надежде, что мы не слишком часто будем их путать.
Но тем не менее, разумеется, путаем. Поэтому они как сделаны - при увеличении числа потоков увеличивается пропорционально максимальное значение этой хэш суммы, в этом в том числе и прирост - мы начинаем реже путать разные пешечные структуры. |
|
|
| номер сообщения: 54-72-8283 |
|
|
|
|
Шахматные программы VII. Основной перебор Stockfish
Итак, мы добрались до самого сердца шахматной программы Стокфиш. Ее основной функции - search. Именно здесь бьется пульс этого движка.
Сейчас мы произведем разбор этой функции. О ее важности уже не раз говорилось на предыдущих страницах. Теперь нам предстоит понять, как основной поиск выглядит в реальной программе. Еще раз напомню, что функцию search можно найти в файле search.cpp. Обзорному описанию содержания этого файла была посвящена предыдущая часть.

Исходные тексты программы Стокфиш можно найти на ее официальной страничке на гитхабе. Все примеры кода ниже приводятся по 18-й версии движка. С этой версией файла search.cpp можно ознакомиться по ссылке:
https://github.com/official-stockfish/Stockfish/blob/cb3d4ee9b47d0c5aae855b12379378ea1439675c/src/search.cpp
Функции pos. вызываемые далее по тексту, вынесены в отдельный файл position.cpp.
Основная функция перебора запускается со строки:
615 Value Search::Worker::search(
Position& pos, Stack* ss, Value alpha, Value beta, Depth depth, bool cutNode)
Задаваемыми параметрами функции являются - позиция из которой будет производиться перебор, затем стек предыдущих и последующих ходов из текущей позиции по ветке варианта, далее значения альфы и беты, глубина на которую следует произвести расчет и тип узла.
На старте производится инициализация параметров и вычисление некоторых простейших функций, на которых мы не будем подробно останавливаться. Основное, что следует отметить - здесь происходит выход на QS, к форсированному перебору, если достигнута предельная глубина (depth=0).
Для большей наглядности каждый этап перебора разделен на выделенные "шаги" (Step). Наиболее важные из них начинаются с 7-го, поэтому по первым шагам пробежимся коротко. |
|
|
| номер сообщения: 54-72-8284 |
|
|
|
|
Step 1. Initialize node
На первом шаге собственно происходит инициализация параметров для узла (позиции) дерева перебора в которой мы сейчас находимся.
Step 2. Check for aborted search and immediate draw
На втором шаге проверяются условия прерывания поиска и возможность ничейного результата.
Step 3. Mate distance pruning
На третьем шаге производим отсечение по мату. Логика проста - если в какой-либо ветке дерева перебора гарантированно ставится мат, допустим в пять ходов, то в остальных ветках нет смысла смотреть глубже. Лучшим вариантом все равно будет ветвь с наиболее коротким матом. По достижении аналогичной глубины расчетов в любой ветке можно прерывать перебор, поскольку он нам больше ничего не даст.
Step 4. Transposition table
На четвертом шаге проверяем, нет ли позиции в таблице перестановок (хеш-таблицах). То есть, не просматривалась ли данная позиция ранее на требуемую или большую глубину. Проверка осуществляется по хеш-ключу. Если позиция присутствует, то перебор из нее проводить не обязательно, используем данные из таблиц.
Step 5. Tablebases probe
На пятом шаге производится проверка эндшпильных баз, если они подключены. Нет смысла проводить перебор, если позиция уже есть в базах.
Step 6. Static evaluation of the position
На шестом шаге производится оценка позиции. Здесь через функцию evaluate(pos) и далее файл evaluate.cpp, происходит обращение к нейросети NNUE.
Это будет так называемая статическая оценка позиции, то есть оценка выполненная нейросетью на основе количества и взаимного расположения фигур, без их перемещения (а не та оценка, которую мы получаем после форсированного перебора qsearch).
Оценка целочисленная и рассчитывается в сантипешках. Это не значит, что цена пешки строго равна 100 единицам, но она достаточно близка к этому значению. Оценка возвращается с точки зрения той стороны, чей ход в данной позиции.
734 else
735 {
736 unadjustedStaticEval = evaluate(pos);
737 ss->staticEval = eval = to_corrected_static_eval(unadjustedStaticEval, correctionValue);
739 // Static evaluation is saved as it was before adjustment by correction history
740 ttWriter.write(posKey, VALUE_NONE, ss->ttPv, BOUND_NONE, DEPTH_UNSEARCHED, Move::none(),
741 unadjustedStaticEval, tt.generation());
742 } |
Надо сказать, что оценка нейросети не используется в переборе в чистом виде. Она предварительно корректируется с помощью некоторой статистики предыдущего перебора, называемой correctionHistory. Таким образом, на данном шаге сначала производится оценка позиции нейросетью, а затем ее корректировка.
Корректировка оценки основана на разнице между чистой оценкой нейросети и оценкой полученной после полноценного перебора из той же позиции. После каждого прохода поиска данные заносятся в специальные таблицы. Со временем correctionHistory накапливает статистику о разнице оценок. Вычисляемая на основании табличных значений величина поправки оперативно вносится на этом шаге. Для пополнения таблиц, позиция совсем не обязательно должна быть идентична предыдущим, достаточно лишь совпадения отдельных ключевых элементов. Для быстрого распознавания одинаковых структур используются хеш-ключи.
Общую структуру системы корректировки оценок можно посмотреть в файле history.h, там же где находятся сортировки по истории. |
|
|
| номер сообщения: 54-72-8285 |
|
|
|
|
*****
После того как мы на предыдущих шагах попытались (и не нашли) позицию среди известных нам, и произвели её оценку, мы наконец-то можем заняться собственно самой позицией.
Всего в основном поиске 21 шаг и наиболее важные среди них шаги с 7-го по 20-й. Именно в них прописаны основное методы производящие сокращения/продления дерева перебора.
Нетрудно заметить, что каждый шаг выглядит достаточно типовым образом. Обычно его предваряют входные условия (if). Если они не выполняются, то шаг пропускается и происходит переход далее, к следующему шагу, где будет предпринята очередная попытка произвести отсечение.
if (...)
{
value = -search(...);
} |
Если условия выполняются, то могут быть проведены некоторые дополнительные процедуры. Далее, либо сразу производится отсечение, либо выполняется перебор (search) ходов из данной позиции на определенных условиях и на определенную глубину. Из него мы получаем динамическую оценку позиции (value), на основании которой принимается решение об отсечении данной ветки, переходе к следующему шагу или выбору другого направления перебора. Но обычно происходит переход к следующему шагу.
Сначала пробуем методы, которые могут привести к немедленному отсечению, без излишнего перебора.
Step 7. Razoring
Step 8. Futility pruning
На седьмом и восьмом шагах производятся отсечения, если перебор приблизился к предельной/заданной глубине (низкой depth).
870 // Step 7. Razoring
873 if (!PvNode && eval < alpha - 485 - 281 * depth * depth)
874 return qsearch< NonPV>(pos, ss, alpha, beta);
876 // Step 8. Futility pruning: child node
878 {
879 auto futility_margin = [&](Depth d) {
... ...
885 };
887 if (!ss->ttPv && depth < 14 && eval - futility_margin(depth) >= beta && eval >= beta
888 && (!ttData.move || ttCapture) && !is_loss(beta) && !is_win(eval))
889 return (2 * beta + eval) / 3;
890 } |
Основной принцип следующий. Если по мере углубления по дереву перебора остался всего один полуход до достижения заданной глубины, а оценка позиции при этом уже настолько плоха, что последним полуходом ее никак не исправить, тогда этот ход можно не генерировать и не рассматривать и прервать перебор уже сейчас. Под плохой оценкой здесь подразумевается оценка ниже оценки основного варианта, обязательно с приличным запасом (futility_margin).
Если последний полуход "за соперника", то он никак не сможет повысить нам оценку, поэтому можно сразу отсекать. Такой метод называется Futility Pruning.
Если последний полуход "за нас", то переходим к qsearch. Обязательно нужно посмотреть форсированные ходы, поскольку хорошее взятие все еще может резко поднять нашу оценку. Тихие ходы можно пропустить. Такой метод называется Razoring.
Правило можно расширить на позиции за два, три и более полуходов до заданной глубины. Но с увеличением дистанции нужно увеличивать и запас по оценке. За расчет величины запаса отвечает отдельная функция. |
|
|
| номер сообщения: 54-72-8286 |
|
|
|
|
Step 9. Null move search
На девятом шаге выполняются отсечения уже известным нам нулевым ходом (Null Move Pruning). Он подробно рассматривался во II и III частях настоящей статьи.
892 // Step 9. Null move search with verification search
893 if (cutNode && ss->staticEval >= beta - 18 * depth + 350 && !excludedMove
894 && pos.non_pawn_material(us) && ss->ply >= nmpMinPly && !is_loss(beta))
895 {
... ...
898 // Null move dynamic reduction based on depth
899 Depth R = 7 + depth / 3;
900 do_null_move(pos, st, ss);
902 Value nullValue = -search< NonPV>(pos, ss + 1, -beta, -beta + 1, depth - R, false);
904 undo_null_move(pos);
906 // Do not return unproven mate or TB scores
907 if (nullValue >= beta && !is_win(nullValue))
908 {
... ...
914 // Do verification search at high depths, with null move pruning disabled
915 // until ply exceeds nmpMinPly.
916 nmpMinPly = ss->ply + 3 * (depth - R) / 4;
918 Value v = search< NonPV>(pos, ss, beta - 1, beta, depth - R, false);
920 nmpMinPly = 0;
922 if (v >= beta)
923 return nullValue;
924 }
925 } |
Аналогично, здесь сначала производится проверка условий допустимости нулевого хода, потом собственно пропуск хода (do_null) и пробный рекурсивный перебор за ту же сторону. Величина сокращения пробного перебора (R) рассчитывается в зависимости от глубины. При положительном исходе пробного перебора выполняется верификационный перебор, который окончательно решает, производить отсечение или нет.
Step 10. Internal iterative reductions (IIR)
На десятом шаге производится сокращение глубины, если позиции нет в хеш-таблице.
929 // Step 10. Internal iterative reductions
932 if (!allNode && depth >= 6 && !ttData.move && priorReduction < = 3)
933 depth--; |
Для таких позиций оказалось выгоднее выполнять перебор с сокращенной глубиной. IIR очень похож на применявшийся ранее метод IID (Internal Iterative Deepening), но подходит к вопросу несколько иначе. |
|
|
| номер сообщения: 54-72-8287 |
|
|
|
|
Step 11. ProbCut
Step 12. A small Probcut idea
На одиннадцатом и двенадцатом шаге выполняется отсечение методом ProbCut.
935 // Step 11. ProbCut
936 // If we have a good enough capture (or queen promotion) and a reduced search
937 // returns a value much above beta, we can (almost) safely prune the previous move.
938 probCutBeta = beta + 235 - 63 * improving;
939 if (depth >= 3
940 && !is_decisive(beta)
941 // If value from transposition table is lower than probCutBeta, don't attempt probCut there
943 && !(is_valid(ttData.value) && ttData.value < probCutBeta))
944 {
... ...
947 MovePicker mp(pos, ttData.move, probCutBeta - ss->staticEval, &captureHistory);
948 Depth probCutDepth = std::clamp(depth - 5 - (ss->staticEval - beta) / 315, 0, depth);
950 while ((move = mp.next_move()) != Move::none())
951 {
... ...
959 do_move(pos, move, st, ss);
961 // Perform a preliminary qsearch to verify that the move holds
962 value = -qsearch< NonPV>(pos, ss + 1, -probCutBeta, -probCutBeta + 1);
964 // If the qsearch held, perform the regular search
965 if (value >= probCutBeta && probCutDepth > 0)
966 value = -search< NonPV>(pos, ss + 1, -probCutBeta, -probCutBeta + 1, probCutDepth,
967 !cutNode);
969 undo_move(pos, move);
971 if (value >= probCutBeta)
972 {
973 // Save ProbCut data into transposition table
974 ttWriter.write(posKey, value_to_tt(value, ss->ply), ss->ttPv, BOUND_LOWER,
975 probCutDepth + 1, move, unadjustedStaticEval, tt.generation());
977 if (!is_decisive(value))
978 return value - (probCutBeta - beta);
979 }
980 }
981 } |
Как мы уже знаем, альфа-бета рассматривает как минимум одно продолжение из позиции на заданную глубину, и если его оценка превышает бету, то производится отсечение. При этом не учитывается, насколько превышена бета. Но ведь можно учитывать величину превышения. Идея метода ProbCut заключается в том, что если оценка намного превышает бету, то перебор этого продолжения можно выполнить и на глубину меньше заданной.
Таким образом сначала выполняется перебор и проверяется оценка позиции на меньшей глубине, и если она окажется гораздо больше беты, то отсечение производится сразу. Можно предположить, что если ветка имеет большой запас по превышению беты на несколько сокращенной глубине, то с немалой долей вероятности она отсечется и на полной глубине, а расчетов можно будет выполнить гораздо меньше.
Величину уменьшенной глубины можно подбирать опытным путем. Специальным тестированием можно определить такой порог и глубину предварительного перебора, что отсечение будет наиболее эффективным и надежным. Если по итогам сокращенного перебора бета будет превышена на достаточную величину, то произойдет отсечение, результаты отправятся в хеш-таблицу и могут быть использованы позже.
ProbCut производит отсечения примерно в той же области дерева перебора что и нулевой ход. При этом он сравнительно менее эффективен. Поэтому как правило он применяется после нулевого хода и как бы "вдовесок" к нему. Работая на уже расчищенном нулевым ходом "поле", он приносит немного пользы, а потому применяется обычно только в ведущих программах.
В Стокфише ProbCut применяется для взятий с высокой оценкой. Код во многом напоминает основной перебор в миниатюре. |
|
|
| номер сообщения: 54-72-8288 |
|
|
| |
|
|
|
|
|
|
|
| Copyright chesspro.ru 2004-2026 гг. |
|
|
|