|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
Не нашел подходящей темы для материалов, которые хотелось бы выложить на форуме. Поэтому пусть будет еще одна тема в разделе компьютерных шахмат.
Здесь можно обсудить вопросы не связанные с новостной повесткой, а в большей степени темы касающиеся работы самих шахматных программ. Не только их структуры, но и применения. Причем не обязательно движков, но и оболочек, обучающих курсов и всего остального.
Тем не менее тема создавалась не из общих соображений, а по вполне конкретной причине. Здесь мне хотелось бы разместить свою статью о принципах работы шахматных программ. Она планируется к выкладке на Хабре. Но решил поместить ее и здесь, в более шахматной среде. Планируется выкладывать ее на форуме с опережением на несколько дней, в порядке предварительного обсуждения.
Вопросы и комментарии приветствуются. Желательно только задавать их после выкладки очередной части текста, так как видимо его придется разбивать на несколько сообщений. Текст будет выкладываться начиная со следующего сообщения. |
|
|
| |
|
|
Шахматные программы I. Вступление
Наверное многие из вас помнят шахматные состязания людей против компьютеров, которые проводились еще относительно недавно. Обычная картина для того времени - на сцене, за шахматным столом, под светом софитов и вспышками фотокамер в своих креслах расположились два человека. Один из них - шахматный гроссмейстер, сосредоточенно смотрит на доску. Второй же - оператор, часто поглядывает на экран монитора, который установлен рядом. Многочисленные зрители затаив дыхание наблюдают за этим действом со стороны.

Но самые глубокие страсти кипят за кулисами. Там не находит себе места многочисленная команда шахматной машины. Их труды только что закончились и они вынуждены просто наблюдать. Здесь находится группа умудренных опытом гроссмейстеров, которые на протяжении многих недель вкладывали в машину как свои огромные знания, так и многовековой опыт всего человечества. Здесь же многочисленная команда программистов, которая помогала им в этом процессе. Наконец, все действо патронируется большой корпорацией, которая не поскупилась оплатить их труды и конечно же задействовала для игры огромные вычислительные мощности. Наконец-то все эти многомиллионные вливания помогут сокрушить человека.
Красочная картина... Но очень далекая от реальности |
|
|
| номер сообщения: 54-72-8226 |
|
|
|
|
*****
Наблюдая много лет за тем, как ломаются копья на многочисленных страницах интернета - в видео, чатах, на форумах или иных открытых обсуждениях, мне становится немного обидно за тех, обычно малоизвестных людей, чьи идеи являются истинным источником силы современных шахматных программ. К сожалению, труды, которые привели к созданию методов, а так же сами эти методы, усилившие шахматные программы до заоблачных высот, до сих пор неизвестны не только широкой публике, но по большей части даже небольшой группе энтузиастов компьютерных шахмат. О том как работают современные шахматные программы, какие методы первичны и делают программы настолько сильными, какие вторичны или совсем малополезны и хотелось бы обсудить в данном цикле статей. Мы коснемся всех основных подходов, которые лежат в основе игры тех шахматных монстров, что прописаны в памяти наших телефонов и компьютеров.
Но сначала небольшой дисклеймер. Автор не является программистом и хотя на то, чтобы досконально познакомиться с основными алгоритмами ушло немало времени, понятно что разработчики сильных шахматных программ обладают гораздо большими знаниями по своему профилю, особенно там где необходимо непосредственное обращение к коду.
Также хотелось бы предупредить, что в этом цикле статей мы не коснемся программ созданных по типу Альфа Зеро, то есть программ использующих перебор на основе метода Монте-Карло и оценку на базе больших сверточных/трансформерных моделей нейросетей глубокого обучения.
Не считая себя достаточно квалифицированным для подробного разбора таких программ, тем не менее полагаю, что некоторое общее обсуждение применяемых в них методов все-таки вполне возможно. Кроме того стоит упомянуть, что с момента появления Альфа Зеро уже прошло много времени и эта программа в значительной степени устарела. В настоящее время ее заменила программа Лила Чесс Зеро (Leela Chess Zero, Lc0), построенная на базе принципов Альфа Зеро. Но эта программа ушла довольно далеко от своего первоисточника, хотя и является ее идейным последователем. Так или иначе, сильнейшей в мире на текущий момент является программа Стокфиш (Stockfish), а она создана на классической базе. Именно программы такого типа мы и будем подразумевать при дальнейшем обсуждении. |
|
|
| номер сообщения: 54-72-8227 |
|
|
|
|
*****
Но прежде, чем приступить к разбору программ, хотелось бы отметить - что же не так в описании выше. В первую очередь, подавляющее большинство сильнейших шахматных программ своего времени разрабатывались командами из двух-трех, а нередко даже из одного человека. А в настоящее время главными являются групповые opensource-проекты Стокфиша, Лилы и недавно взлетевший проект Reckless, чьи участники работают на безвозмездной основе. На протяжении всей истории компьютерных шахмат по настоящему крупные компании подключались к разработке лишь дважды и вы их все прекрасно знаете. Это IBM и Гугл. По-видимому, такое происходило из-за того, что в данной отрасли вращается относительно мало денег и крупные корпорации вмешиваются только когда им светит явный, но кратковременный выигрыш, преимущественно медийно-финансового плана. Кроме того, улучшать программы не так-то просто и проблему нельзя только лишь завалить деньгами. В обоих случаях имелся конкретный план.
Еще одна проблема связана с самыми разнообразными слухами, циркулирующими в интернете, а они по сути являются отражением общественного мнения. Так, уже многие годы в сети периодически вспыхивают обсуждения, где люди пытаются разобраться, как же работают шахматные программы и почему они так сильны. Здесь укоренилось два основных мнения. Первое упирает на некие "базы", собранные или сгенерированные людьми. Или как вариант на некие "гроссмейстерские знания", заботливо заложенные в программу квалифицированными шахматистами.
Первым на таком подходе погорел Каспаров в известных матчах с Дип Блю. Он часто уходил на малоизвестные варианты, но оказалось что компьютер вполне разбирается даже в совсем неизвестных дебютных ответвлениях. Для Дип Блю хватило обычного счета, чтобы играть очень сильно. Эндшпильные базы тогда тоже почти не использовались, так как даже в конце партии на доске оставалось немало фигур, и поэтому компьютер обычно не добирался до использования баз.
Те, кто разбирал код сильных шахматных программ знает, что внутри кода нет никаких "гроссмейстерских знаний", как в виде неких "баз знаний", так и в виде большого набора отдельных шахматных правил. Конечно определенные правила внутри есть, но они в подавляющем большинстве не шахматного характера. Но даже и правила непосредственно относящиеся к шахматам далеко не высшего уровня. Обычно правила в переборе не связаны с шахматами вообще и в значительной степени универсальны. Например, код поиска ведущей шахматной программы Стокфиш практически без изменений используется в лучших программах таких игр как сеги и сянцы. Если китайские сянцы еще похожи на обычные шахматы, то японские сеги кардинально отличаются и тем не менее их разработчики находят, что код поиска Стокфиша все равно лучший.
Что же касается возможности подключения внешних баз, нетрудно убедиться, что кроме дебютных и эндшпильных, других не существует. Но как указано выше, первые мало чего дают практически, а до вторых редко доходит по количеству фигур на доске. Движок вполне справляется своим счетом.
Даже если не уклоняться от проторенных путей, дебютные знания в плане силы игры обычно дают не больше чем людям, то есть прибавку всего в несколько десятков пунктов рейтинга, и оказывают какое-то влияние только когда соперники относительно равны по уровню. А в настоящее время даже это незначительное преимущество сошло на нет, так как программы не делают в дебюте фатальных ошибок. То же касается и эндшпильных баз.
Таким образом, шахматисты высокой квалификации, в том числе и гроссмейстеры, оказали мало влияния на развитие шахматных программ, хотя нередко их и выдвигали на передний план. В то же время истинные разработчики - программисты, часто оказывались задвинуты в тень. Конечно некоторые шахматные знания невысокого уровня требовались для оценочной функции, но авторы сильнейших программ обычно обходились знаниями уровня собственного первого - второго шахматного разряда. А если в отдельных случаях нанимались высококвалифицированные шахматисты, то они ничем не могли помочь. Бывало, что некоторые авторы едва умели играть в шахматы, но это не мешало их программам подниматься на самый верх. |
|
|
| номер сообщения: 54-72-8228 |
|
|
|
|

Второе мнение, циркулирующее в широких кругах - ссылка на то, что компьютер "все посчитал", иногда чуть ли не до конца партии. Но как нетрудно заметить, почему-то у начинающих авторов шахматных программ, реализовавших только обычный перебор вариантов, движки играют не сильнее первого спортивного разряда, а временами и слабее, несмотря на мощные современные машины. То есть они даже слабее программ конца 70-х, запускавшихся на железе в тысячу раз медленнее. Как оказалось, "тупой перебор", о котором ведется столько разговоров, тупо не работает.
При том ветвлении, которое существует в шахматах, дерево простого перебора разрастается мгновенно, что не позволяет быстро набирать глубину и компьютер при таких условиях играет крайне слабо. Фактически полный перебор стопорится уже на глубине 5 - 6 полуходов (3 хода с обеих сторон) даже на самых скоростных машинах. Железо хоть и важно, но ни разу не решает вопрос.
Наконец, хотелось бы упомянуть вездесущие ныне нейросети. Теперь именно они стали новым "чудо-средством" и ключевым моментом всех объяснений. Разговоры о том, что практически только они и определяют силу игры шахматных программ ведутся с момента появления Альфа Зеро. Это отчасти верно в отношении программ созданных по ее типу. Но в программах собранных на классической базе, которые мы рассмотрим ниже, нейросети лишь одна из составляющих силы игры. Эти сети крайне малы по объему выполняемых в них вычислений, а потому на самом деле не особо "умны". В современных программах классические методы перебора все еще играют главную роль в формировании силы игры, хотя оценочная функция на базе нейросети уже может в чем-то с ними сравниться (но, откровенно говоря, сравнивать столь ортогональные направления довольно затруднительно). |
|
|
| номер сообщения: 54-72-8229 |
|
|
|
|
*****
Что ж, после такого длинного вступления, давайте обсудим реально важные составляющие шахматных программ.
Для силы игры шахматной программы в первую очередь важны три фактора. Это железо, оценка и поиск. Остальные факторы малозначимы или же являются элементами вспомогательного характера (но наверное не надо разъяснять, что даже малозначимая деталь, при недолжном исполнении, может загубить любую программу).
В силу обозначенных выше причин и несмотря на многочисленные рассуждения об обратном, наименее значимым среди них видится фактор железа.
Еще в 80-е годы было установлено (а предполагалось и ранее), что сила программ значительно растет с увеличением глубины, если перебор осуществляется без потерь или практически без потерь информации вследствие отсечений. Это верно и в наши дни - с увеличением времени на обдумывание, или же скорости центрального процессора, глубина увеличивается, а следовательно сила игры последовательно и существенно возрастает.
Тем не менее, как уже упоминалось выше, хотя глубина растет, дерево простого перебора растет еще быстрее. Так что фактор железа у нас на третьем месте. Помимо того, мощность железа, это в общем-то технический параметр. Поэтому мы не будем подробно останавливаться на нем, и в дальнейшем будем ссылаться на скорость железа только по необходимости.
Если же рассматривать факторы, которые непосредственно влияют на выбор хода, то можно сказать что программа состоит из двух частей - оценки позиции (Evaluation) и поиска по дереву вариантов (Search). Оценочная функция производит оценку качества позиции на основе количества и взаимного расположения фигур, без их передвижения. Результатом является число, которое используется поиском для отбора направлений для перебора. То есть для решения в каких ветках продлить, а в каких сократить или полностью прекратить перебор - это так называемые продления, сокращения и отсечения. Позиция из которой стартует перебор называется корневой (Root). Просчитываемые из корня ходы при переборе вариантов формируют своеобразное дерево, позиции в котором называются узлами (Node).
Оценку позиции на основе выделенных параметров долгие годы не удавалась существенно улучшить. Все простые и легко вычисляемые факторы были быстро найдены, а сложные либо имели ограниченную применимость, для специфических расстановок фигур, либо требовали больше ресурсов на вычисление, чем приносили выгоды, т.е. работали в минус и от них отказывались. Тем не менее уровень оценочной функции все-таки медленно рос, но она играла явно второстепенную роль в сравнении с наиболее значимым фактором шахматных программ - поиском по дереву вариантов.
Уровень оценочной функции резко поднялся после пришествия нейросетей - в программах на классической базе нейросеть заменила именно оценочную функцию. Но все равно нейросети у таких программ остаются еще маленькими и слабыми, поэтому и не так значимы как хотелось бы. Оценочную функцию мы подробно рассмотрим позже, а пока обратимся к самому важному - поиску.
Поиску по дереву вариантов, иначе говоря - перебору, обычно придается мало значения. Многие считают, что движок перебирает все возможные ходы на определенную глубину, может быть с некоторыми "оптимизациями", и больше ничего не делает. Немного парадоксально, что такому важному фактору шахматных программ уделяется так мало внимания в общественном сознании. Тем не менее именно перебору, или в более узком смысле - отсечениям, мы в первую очередь обязаны силой игры современных шахматных программ на классической базе.
Отбрасывая заведомо не лучшие ходы, поиск современных движков ограничивается просмотром в среднем только около 1 - 2 продолжения в каждой позиции дерева перебора, при 30 - 40 возможных. То есть программы используют крайне селективный перебор, почти без ветвлений, и потому, и только потому, достигают большой глубины. А уже по достижении большой глубины движок может досчитываться до конкретных последствий своих действий и даже при слабой оценочной функции находить сильные ходы.
Опять же, влияние прироста скорости железа на этом фоне выглядит тускло. К примеру, если бы мы увеличили скорость машины в 1000 раз, как скажем было в свое время у Дип Блю относительно современных ему ПК, то это ускорение останется постоянным, сколько бы позиций мы не просмотрели. Тогда как например только альфа-бета отсечения увеличивают скорость набора глубины в тысячу раз, когда рассмотрена 1000 позиций, в миллион раз после рассмотрения миллиона позиций, в миллиард раз после рассмотрения миллиарда позиций и т. д. То есть скорость растет вместе с перебором. Ни одно железо так не может. |
|
|
| номер сообщения: 54-72-8230 |
|
|
|
|
*****
Итак, мы установили, что на выбор ходов программой непосредственно влияют поиск по дереву вариантов и оценочная функция. Сначала попробуем в общих чертах понять как функционирует перебор.
Обход дерева вариантов грубо можно разделить на две части. Сначала выполняется основной перебор на определенную глубину для всех значимых ходов. По достижении заданной глубины перебора, он не прерывается, но в дерево теперь допускаются только форсированные ходы - в первую очередь взятия и иногда шахи.
Такой перебор называется Форсированный вариант (Quiescence Search, ФВ, QS). Он необходим, потому что нельзя заранее предугадать на какую глубину следует считать и поэтому обычный перебор на фиксированную (заданную) глубину может внезапно прекратиться на середине разменов. Слабая оценочная функция, в том числе слабая нейросетевая, не в состоянии по взаимному расположению фигур отличить реальное взятие, например ферзя, от его размена. Досчитав до заданной глубины программа будет полагать, что она приобрела ферзя, тогда как следующим ходом варианта произойдет ответное взятие, до которого перебор уже не досчитывает.
Поэтому по окончании основного перебора программа обязательно должна произвести все размены и досчитаться до "спокойной" (quiescence) позиции. Только тогда можно вызывать оценочную функцию и давать числовую оценку этой позиции. Quiescence Search - это важнейшая часть шахматной программы, которую предложили еще классики - Тьюринг и Шеннон.
Но мы сосредоточимся на основном переборе. Подробнее порядок обхода всего дерева, а также Quiescence Search мы рассмотрим позже.
В следующих частях мы поговорим об основных методах ограничения перебора, коснемся терминологии и некоторых второстепенных методов, поговорим об оценочной функции, а так же пробежимся по коду поиска Стокфиша - самой сильной шахматной программы в мире.
Продолжение следует... |
|
|
| номер сообщения: 54-72-8231 |
|
|
|
|
| Здесь заканчивается первая часть статьи. Остальные буду выкладывать позже. Ориентировочно с интервалом в два-три дня, если не будет каких-то затруднений. По крайней мере пока так планируется. |
|
|
| номер сообщения: 54-72-8232 |
|
|
|
|
Вообще да, я фактически везде встречаю то, о чём автор говорит (а, это Вы и есть. Оставлю для истории всё равно  ). Причём даже у гроссмейстеров, которые программами уже 20+ лет при подготовке пользуется. ). Причём даже у гроссмейстеров, которые программами уже 20+ лет при подготовке пользуется.
И про таблицы, и про базы, и про "всё посчитали", а про то, что фактически главное, что улучшилось - это спекулятивное расширение алгоритма альфабета на чёрно-белые играх типа шахмат, никто и не говорит.
Тут вот есть очень в тему график - https://github.com/official-stockfish/Stockfish/wiki/Useful-data#branching-factor-of-stockfish , который показывает фактор ветвления в зависимости от версии и от глубины со стартовой (вроде бы) позиции. Если кому-то кажется, что разница 1,7 и 1,9 невелика, то вот можно напомнить, что (1,9/1,7) ^ 30 это 29, то есть стокфишу 10, чтобы дойти до глубины 30, понадобится приблизительно в 28 раз больше узлов, и чем дальше - тем больше эта разница.
Кстати, там же ещё есть данные про таблицы - https://github.com/official-stockfish/Stockfish/wiki/Useful-data#elo-gain-using-syzygy
К вопросу об их важности при реальной игре, даже до всяких нейросетей 6-фигурные таблицы были там 15 эло примерно. |
|
|
| номер сообщения: 54-72-8233 |
|
|
|
|
| Вообще в последний раз, когда я проверял, в районе вроде бы SF16, Quescence Search стоил чуть больше 150 эло (если при достижении глубины 0 просто возвращать статическую оценку вместо него). |
|
|
| номер сообщения: 54-72-8234 |
|
|
|
|
Один из авторов Дип Блю когда-то писал, что QS дает столько же, как и углубление на 4 полухода без QS. Правда с тех пор много воды утекло - современное понятие глубины стало уж очень специфическим.
Если в целом, измерение полезности каждого метода непростое занятие. Поиск современных программ настолько изощренный, что даже если отключишь один метод, то его "подстрахует" другой метод и объективного измерения не получится.
Для примера, допустим один патч дает 100 пунктов, при отдельном измерении, и другой тоже 100 пунктов. Но предположим отсекают они 95 % одних и тех же узлов. Тогда в сумме они дадут скорее всего только 105 пунктов. Если конечно не тестировать их один поверх другого.
Если же попытаться их "упростить", то по отдельности каждый из них даст лишь -5 пунктов регресса, поскольку при удалении одного из патчей его узлы сразу же "подхватывает" другой. Но если убрать оба, то регресс сразу возрастет до -105 пунктов. Такая вот забавная арифметика. |
|
|
| номер сообщения: 54-72-8235 |
|
|
|
|
Ну это понятно, с другой стороны, именно qsearch никто не страхует особо, то есть тут можно куда более прямо всё сделать.
Что имеется в виду - он же вызывается в самом начале функции search по условию
if (depth = 0)
return qsearch(от всего)
Если же это поменять на
if (depth = 0)
return evaluate(pos)
то никто и ничего не страхует.
Принципиальное отличие от эвристик отсечения разных в том, что тут идёт безусловное отсечение по достижению глубины 0, в то время как в эвристиках отсечения они идут одна за другой и действительно одна может страховать другую.
Ну есть ещё применения qsearch во всяких других местах, но они там единицы эло дают, да и когда я этот тест делал, был он только в razoring, ну а эта эвристика почти ничего не даёт сама по себе. |
|
|
| номер сообщения: 54-72-8236 |
|
|
|
|
Шахматные программы II. Отсечения
Самой важной частью шахматной программы, которая вносит основной вклад в силу игры, является направленный перебор. А самой главной частью направленного перебора являются отсечения и сокращения наиболее неперспективных ходов. Отбрасывая наименее важные ветви, программа вкладывает ресурсы машины в наиболее перспективные варианты. Чем больше отсекает программа, тем дальше она углубляется по дереву вариантов. И чем глубже она считает, тем сильнее играет.

Если бы программа считала до конца - до конечного результата в партии, то ей не потребовалась бы даже оценочная функция. Исторически, программы считали все глубже и глубже, и соответственно играли все лучше и лучше.
Здесь мы рассмотрим три наиболее значимых метода ограничения перебора вариантов. Они наиболее действенны, поскольку применяются по всей глубине дерева, хотя и срабатывают не в каждой позиции. Именно они приводят к наибольшему сокращению ветвления вариантов в дереве перебора, а значит и к наибольшему углублению.
Среди них наиболее важным являются Альфа-Бета отсечения (Alpha-Beta Pruning). Это метод отсечений без потерь, то есть он всегда выдает тот же ход и оценку позиции, что и полный перебор, независимо от качества оценочной функции, но делает это гораздо быстрее.
Двумя другими важными методами являются методы отсечений/сокращений с потерями информации. Такие методы обычно называют эвристиками. Один из них, это метод отсечений с помощью пропуска хода - иначе говоря, нулевой ход (Null Move Pruning), второй - метод сокращений на поздних ходах (Late Move Reductions, LMR).
В большинстве позиций отсечения начинаются с пробного перебора и попытки отсечь нулевым ходом, затем программа пытается отсечь альфа-бетой и если с ее помощью отсечь не получается, тогда подключается LMR и сокращает глубину перебора на оставшихся ходах.
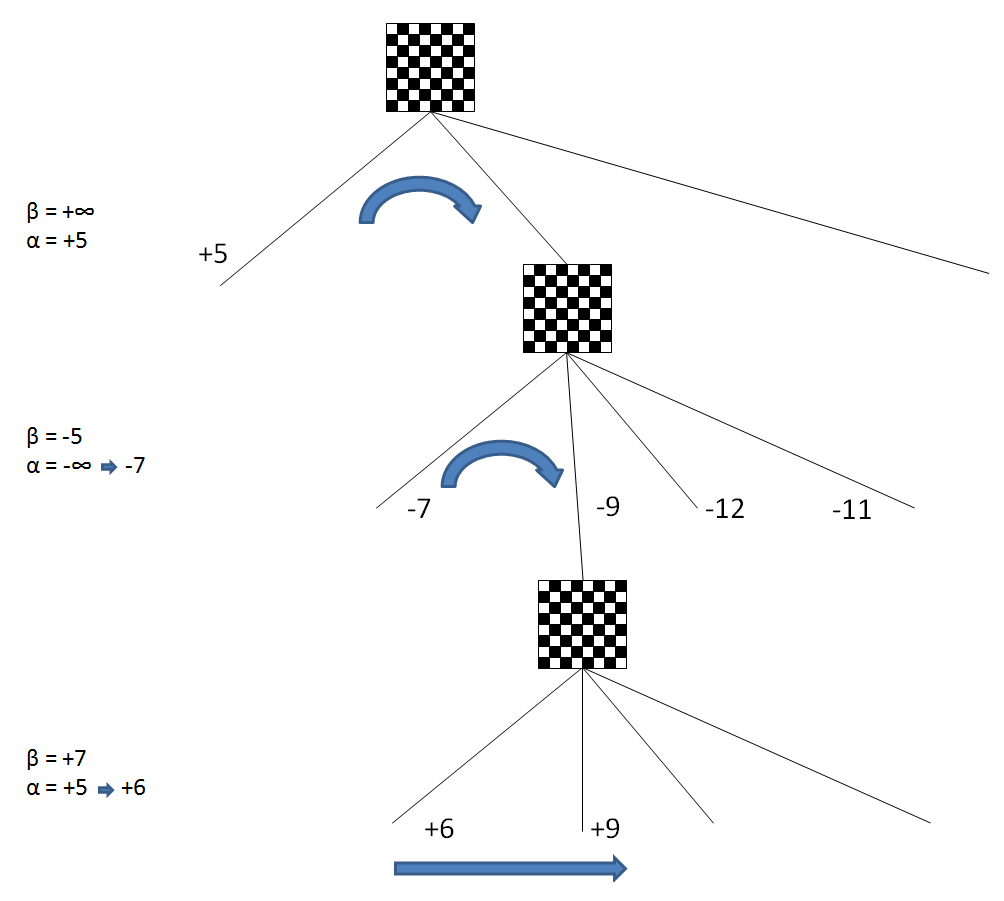
Давайте рассмотрим эти методы более подробно. Ниже приведены схемы небольшого участка дерева перебора. Верхняя диаграмма предполагает позицию с которой начинается перебор вариантов или позицию где-то в глубине дерева, на локальном участке. Каждая линия, это один из возможных ходов в данной позиции, который перебирается на определенную (заданную) глубину. По ним ход за ходом получаются следующие позиции на бОльшую глубину, из которых генерируются следующие ходы и т. д.
Просчитаем на схеме ниже первый возможный ход в начальной позиции на заданную глубину и получим его оценку (например +5). Теперь перейдем к проверке второго возможного варианта. Но сначала попытаемся отсечь его с помощью нулевого хода. |
|
|
| номер сообщения: 54-72-8237 |
|
|
|
|
Общая очередность перебора будет следующая:
1. Principal Variation (PV)
Как уже написано выше, сначала смотрим основной вариант (PV). Это любая ветка в начале перебора или лучшая с предыдущего перебора, если таковой ранее проводился, но c добавлением полухода глубины. На схеме ниже она находится слева.
Допустим мы исследовали основной вариант и получили оценку +5. Теперь переходим к следующему варианту, который уже попытаемся отсечь.
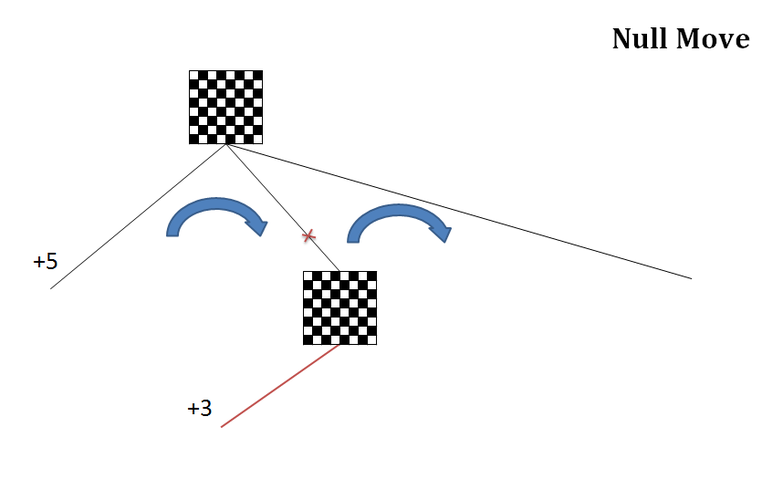
2. Null Move Pruning
Используя метод нулевого хода попытаемся отсечь вторую ветку по-быстрому, до начала основного перебора. Для этого после первого хода варианта производим в ветке "нулевой" ход и далее пробный перебор с сокращенной глубиной. Иначе говоря сейчас в нижней позиции на схеме ход противника, но мы пропускаем его и снова ходим за себя. Мы нарушаем правила шахмат, но нам нужно лишь получить информацию об отсечении.
Главный принцип - если даже после двух наших ходов подряд, оценка все равно ниже чем у основного варианта (на схеме +3 меньше, чем +5), то такой вариант никуда не годится, поэтому сразу же отсекаем его.
Логика следующая - поскольку право хода обычно является преимуществом, то два хода подряд просто огромное преимущество. И если даже они не помогли, значит вариант плох и не достоин рассмотрения. Можно отсекать. Конечно, для случаев цугцванга есть специальные ограничения.
Если же мы напротив, получили оценку выше, чем у основного варианта (допустим +18), значит у хода есть некоторые перспективы. Мы отменяем нулевой ход и приступаем к основному перебору. Генерируем ходы из нижней позиции на схеме теперь уже по всем правилам шахмат. |
|
|
| номер сообщения: 54-72-8238 |
|
|
|
|
3. Ordering
Соответственно генерируются ответы соперника и производится их сортировка в порядке перспективности. По каким правилам - будет описано ниже.
4. Alpha-Beta Pruning
Теперь попытаемся снова отсечь, на этот раз альфа-бетой.
Схема альфа-бета отсечений, после неудачного применения нулевого хода (+18):
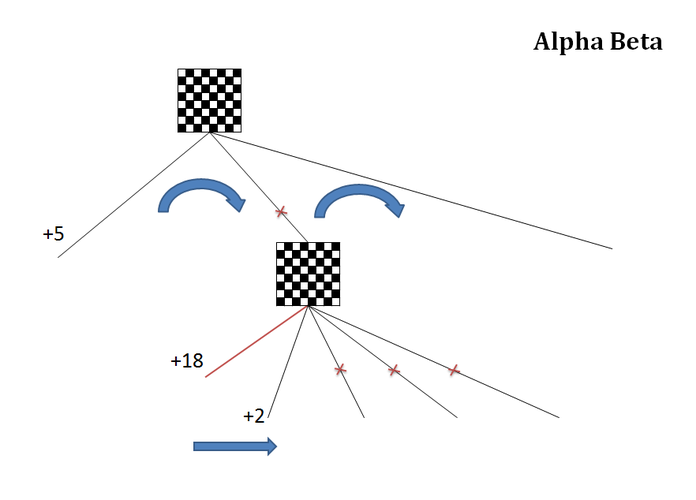
Смотрим на схеме ходы из нижней позиции. Сначала делаем первый ход по сортировке. Исследуем его на полную (то есть заданную) глубину.
Допустим, мы получили для первого рассмотренного хода оценку +2. Это предполагаемый ответ нашего соперника. Лучше чем на +2 в данном варианте мы уже не можем рассчитывать, поскольку здесь ход выбирает соперник, а на ответ с большей оценкой он не согласится. Отсекаем.
Действительно, мы предполагаем, что соперник не враг себе и выберет лучший ход для себя, а не для нас. То есть из всех ответов это будет ход с наименьшей оценкой. Если у других ответов оценка будет выше +2, то он их не выберет, а если ниже, то он их выберет, но тогда оценка станет еще меньше. В таком случае оценку выше +2 мы никак не получим. А это в свою очередь не устраивает уже нас, поскольку у нас в запасе есть основной вариант с оценкой +5, который мы и выберем. Значит никакие ответы в текущем варианте нас уже не устроят и нет смысла их рассматривать. Следовательно, в головной позиции схемы отсекаем второй вариант и переходим к следующему.
Если говорит технически, то +2 меньше чем +5, а значит у нас произошло отсечение по бете. Правда в реальных программах обычно используют инвертированную модель перебора и отсекают по превышении беты. Но здесь мы не будем на этом останавливаться.
Из схемы выше очевидно, что в первую очередь необходимо смотреть ответы, которые вызовут отсечение. Поэтому перебор следует начать с варианта, который принесет нам оценку ниже +5. Иначе перебор может затянуться. Конечно мы не можем заранее знать, какой ход принесет нам такую оценку, но можем попытаться хотя бы провести предварительную сортировку ходов на основании формальных признаков. Такая сортировка выполняется перед началом основного перебора по пункту 3.
В человеческих шахматах принцип альфа-бета отсечений тоже используется. В двух словах его логику можно описать так:
"Если в каком-то варианте мы сразу же наткнулись на сильный ответ противника, то вариант можно отбросить немедленно". То есть забраковать, не рассматривая остальные ответы. Действительно, какой смысл идти на плохой вариант? У оппонента тут есть как минимум один сильный ход и соответственно хорошая игра. Таким образом, человек может сильно экономить время на расчете подобных вариантов.
Но чтобы реализовать альфа-бету для машины, сперва надо бы определить что такое "сильный ответ" и как его найти "сразу". Первое понятно - мы просто сравниваем с оценкой основного варианта, и если она лучше, то немедленно отсекаем текущий вариант.
Второе сложнее. Человек сразу видит сильный ответ, а для машины нам придется предварительно отсортировать технически возможные ходы из позиции в порядке их выгоды для соперника. "Сильный ответ противника", это соответственно ход с наименьшей оценкой для нас. Но поскольку мы заранее не знаем какие будут оценки ходов не проводя перебора, то попробуем их оценить предварительно, на основании простых внешних признаков.
Итак, перед нами стоит задача начать перебор с ответа, оценка в котором предполагается быть меньше или равной +5. Тогда мы сможем отсечь вариант немедленно. Пусть не будет никаких лишних вычислений. Смотрим только простые признаки. Теперь вернемся к пункту 3 и рассмотрим методы сортировки. |
|
|
| номер сообщения: 54-72-8239 |
|
|
|
|
3. Ordering
Необходимо отсортировать ходы в порядке убывания их силы для соперника. Исторически сложился следующий порядок выборки ходов:
а) Сначала проверяем в хеш-таблицах, не просматривалась ли эта позиция ранее с требуемой или большей глубиной. Если такая позиция присутствует, то берем лучший ход для нее из таблицы.
Хеш-таблицы, или таблицы перестановок (Transposition table), это таблицы уже просматривавшихся ранее позиций с известной оценкой и лучшим ходом в них. По мере перебора в таблицу заносятся новые позиции, а старые удаляются по превышению выделенного объема оперативной памяти. Для хранения и поиска позиций используются хеш-ключи по методу Зобриста.
б) Смотрим "выгодные" взятия. То есть взятия с положительным материальным балансом, отсортированные по данному параметру. Взятия резко повышают оценку сопернику, иначе говоря "выгодность" хода, поэтому разумно предположить, что они будут отсекать в первую очередь.
Стандартные методы для данной процедуры - MVV/LVA или SEE.
MVV/LVA сортирует все возможные взятия в позиции по принципу соотношения ценности атакующей и атакуемой фигуры. В первую очередь смотрим взятие, где наименее сильная фигура бьет наиболее сильную, затем смотрим взятие с меньшей разницей и т. д.
SEE - сортировка взятий в позиции по соотношению числа и силы фигур нападающих и защищающих некоторое поле шахматной доски. То есть подсчет "выгодности" каждого размена отталкивается от общего числа нападений и защит на определенное поле. Это то же самое, что подсчет числа "боёв" на определенное поле у людей, которые ленятся считать размены перебором вариантов.
SEE - очень "ходовой" метод. Его используют во многих частях программы для разных целей. В старых программах его даже использовали вместо ФВ (QS), чтобы не тратить ресурсы и память для расчета разменов.
в) Смотрим тихие ходы. Сначала, это так называемые "Киллеры" (Killers), иначе говоря "убойные ходы" - ходы, которые недавно вызывали отсечение.
Логика заключается в том, что в похожих позициях обычно и отсекающие ходы одинаковые. Значит надо в первую очередь попробовать ходы недавно вызывавшие отсечение. Запоминаем два или три последних отсекавших тихих хода и рассматриваем их по принципу - самый последний отсекавший смотрим в первую очередь. По мере продвижения по дереву ряд киллеров обновляется новыми отсекавшими ходами, которые вытесняют наиболее старые. Для каждой глубины ведем отдельный список киллеров.
г) Смотрим тихие ходы в порядке статистики истории отсечений (History).
По мере перебора мы ведем статистику отсекавших ходов, но уже безотносительно подобия позиции. Ходы которые отсекают чаще и бОльшие ветки поднимаются в списке, а остальные соответственно опускаются. Будем вести таблицу таких отсечений и динамически ее обновлять. В современных программах таких таблиц несколько. Они ведутся в том числе и для взятий.
д) "Невыгодные" взятия и остальные ходы.
 |
|
|
| номер сообщения: 54-72-8240 |
|
|
|
|
*****
Теперь представим, что мы отсортировали ходы, посмотрели первый ответ соперника и отсечения альфа-бетой не произошло. Допустим оценка первого хода в схеме выше была не +2, а +7. Это больше беты, а значит отсечения нет - надо смотреть следующие ответы. Здесь, для ходов с номером по сортировке >1 возможен еще один способ сокращения перебора. Он называется LMR.
5. Late Move Reductions (LMR)
Выше мы предположили, что после рассмотрения первого ответа соперника получена оценка +7. Давайте обновим схему:
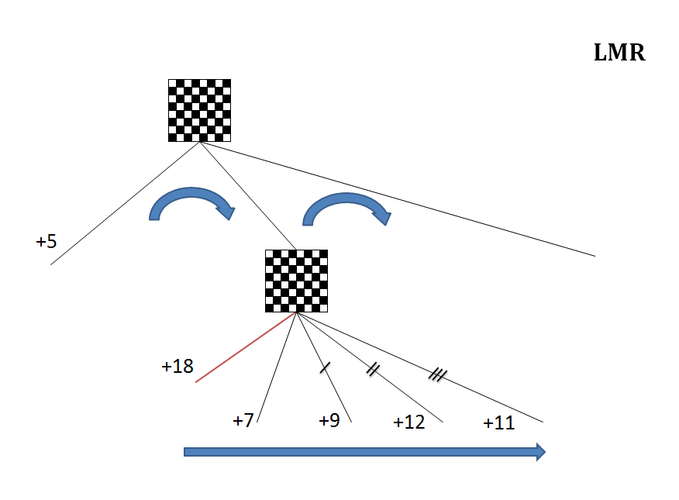
Суть метода в том, что при нормальной сортировке, оценки ходов после первого будут только расти, а значит соперник их все равно не выберет. Поэтому мы можем сэкономить и рассмотреть их с сокращенной глубиной. Причем, чем выше номер хода по сортировке, тем сильнее мы можем подрезать ветку. Если же вдруг какой-то ход покажет неожиданно низкую оценку, то его всегда можно пересчитать на полную глубину.
Иначе говоря, с оценкой +7 первый ход по сортировке не вызывает отсечения. Нужно смотреть следующие по номеру ходы (ответы). При идеальной сортировке их оценки после перебора должны быть ещё выше, а значит отсечения снова не состоятся. Сопернику такие ответы тоже не нужны - оценка растет для нас, а значит для него эти варианты только хуже. Выбор хода за ним, и он просто не будет так ходить. И выберет первый ход с оценкой +7, а потому мы также должны ожидать именно такой ответ.
Казалось бы, тогда и не нужно смотреть остальные ходы, если они никому не нужны. Но сортировка у нас простейшая - явно не идеальная. Поэтому смотреть ходы после первого нам все-таки придется. Вдруг на одном из них получим оценку ниже +7 и тогда лучший для соперника вариант изменится? Или даже получим оценку ниже +5 (бета) и отсечение все же произойдет?
Здесь возможен компромисс. Поскольку сортировка у нас более-менее справляется, то ходы с оценкой ниже +7 будут редко появляться в переборе, а значит давайте смотреть ходы после первого с меньшей глубиной. И чем больше номер хода по сортировке, тем с меньшей глубиной его можно рассматривать, поскольку вероятность, что он выйдет на первую линию уменьшается. То есть, если ход, который идет вторым номером разумно "подрезать" совсем чуть-чуть, то глубину каждого следующего хода будем сокращать все больше и больше. В этом суть метода Late Move Reductions (LMR) - сокращения на поздних ходах.
Но если какой-то ход все-таки покажет неожиданно низкую оценку, то его нетрудно пересчитать с полной глубиной. Как показывает практика, сокращать глубину на всех поздних ходах и изредка производить повторные переборы на полную глубину гораздо выгоднее, чем считать все подряд.
Итак, если сортировка хороша, то по мере просмотра ходов их переборная оценка должна подниматься (+9, +12, +11). Но если оценка для какого-то из поздних ходов неожиданно упадет, то скорее всего мы напортачили с сортировкой. Если оценка очередного хода будет ниже оценки лучшего ответа соперника (+7) или даже беты (+5, т.е. хуже основного варианта), то мы производим перерасчет такого хода уже с полной глубиной.
Если перерасчет подтвердит понижение оценки, то значит у нас поменялся лучший ответ соперника. Может даже произойдет отсечение, если оценка будет ниже беты. А если нет, то значит случилась ложная тревога - перебор с сокращенной глубиной давал некорректную оценку. Если нет отсечения по бете, то продолжаем смотреть оставшиеся ходы с сокращенной глубиной, не исключено, что для какого-то из них оценка снова обвалится.
*****
Подведем итоги. Рассматривая в совокупности все три метода отсечений, мы можем увидеть, что отсечения или сокращения происходят чуть ли не в любом случае, практически всегда. Не тем, так другим способом.
Данные методы определяют силу игры современных шахматных программ. Резко сокращая перебор, программы резко наращивают глубину. Видят далеко, учитывают все последствия, тем самым сильно повышая качество игры.
Следует предупредить, что описание методов выше идет в терминах минимакса. А в реальных программах, у любого мало-мальски сильного движка реализована схема негамакса. То есть все рассуждения реализованы с инверсией. Логика не меняется, но берется с противоположным знаком. Поэтому, например отсечения в программах происходят по превышению беты. В IV части мы обсудим это подробнее. В целом, суть перебора остается прежней, а написанное выше все же полагаю проще для понимания.
В следующей части мы перейдем от локального рассмотрения методов на отдельных узлах, к обсуждению их полезности в более широком контексте всего дерева перебора. Если кому-то не очень интересно дальнейшее погружение в тонкости организации перебора, он может прочитать сокращенную версию этой статьи, сразу перейдя к обсуждению оценочной функции в V части, а оттуда к заключению в последней части.
Продолжение следует... |
|
|
| номер сообщения: 54-72-8241 |
|
|
|
|
Ну вообще, конечно, методов отсечений существенно больше
А так ну я не знаю, отсечения непосредственно в цикле поиска дают в сумме примерно в 3 раза, чем тот же NMP. |
|
|
| номер сообщения: 54-72-8242 |
|
|
|
|
Vizvezdenec: Ну вообще, конечно, методов отсечений существенно больше
А так ну я не знаю, отсечения непосредственно в цикле поиска дают в сумме примерно в 3 раза, чем тот же NMP. |
Об остальных отсечениях расскажу, когда дойдем до описания кода Стокфиша. А пока только самое важное. В цикле находятся альфа-бета и LMR. Вдвоем они очень сильны. Плюс остальные методы.
Все указанные выше методы дают наибольшее сокращение бренчинг-фактора, а значит в итоге приводят к наибольшему углублению. В историческом контексте NMP черезвычайно важен. По большей части именно его заслуга, что ветвление в программах на протяжении 90-х - первой половины 00-х сократилось с примерно 5,5 до 3,5. Но об этом в следующей части статьи. |
|
|
| номер сообщения: 54-72-8243 |
|
|
|
|
Шахматные программы III. Дерево перебора
В третьей части мы взглянем на дерево перебора в общем контексте поиска. Увидим, каким образом методы отсечений из предыдущей части влияют на дерево в целом или на значительные его части, а также для полноты картины оценим влияние этих методов в историческом контексте. Эту и следующую части можно пропустить, если общего описания основных методов ограничения перебора ранее кажется достаточным.
 |
|
|
| номер сообщения: 54-72-8244 |
|
|
|
|
Итак, давайте взглянем на дерево перебора более обобщенно. Сначала рассмотрим только дерево альфа-бета отсечений с идеальными сортировками, пока что без нулевого хода и LMR. Некоторая часть типичного дерева для такого перебора показана на рисунке ниже. Верхний узел (позиция) не обязательно относится к корневому. Штриховыми линиями намечены ходы удаленные из перебора альфа-бетой. На схеме показаны только три возможных хода из каждой позиции, но в реальном дереве шахматной игры их, естественно, будет около 30 - 40.
Как нетрудно заметить, отсечения в дереве происходят не на каждом узле. По мере увеличения глубины по каждой ветке альфа-бета отсекает как бы "через раз". Если на каком-то узле достаточно рассмотреть один ход для отсечения остальных вариантов, то на следующей глубине приходится уже смотреть все продолжения. Далее в глубину ситуация повторяется. Это вызвано тем, что альфа-бета отсечения производятся по превышению беты, а поскольку на некоторых узлах бета равна бесконечности, то соответственно ее невозможно превысить и отсечений не происходит.
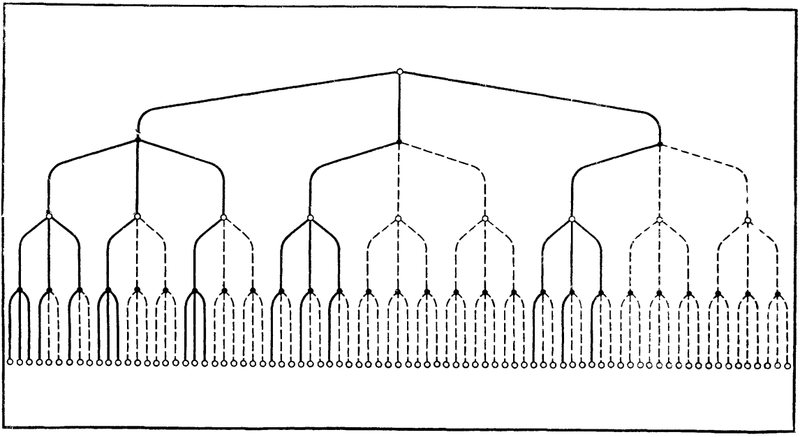 Иллюстрация дерева альфа-бета отсечений из книги "Машина играет в шахматы" (1983)
Позиции, или иначе говоря - узлы, nodes, где возможны отсечения альфа-бетой, принято называть Cut-nodes. Узлы где они невозможны, называются All-nodes - буквально узлы, где рассматриваются все возможные продолжения. Количество узлов обоих типов в дереве перебора примерно одинаково. Более наглядно типы узлов показаны на изображении ниже. Как видим, на схеме еще присутствуют узлы, обозначенные как PV-nodes. Это узлы основного варианта расчетов - цепочки лучших ходов и сильнейших ответов на них, которую мы обычно видим на экранах как "первую линию". На подобных схемах ее как правило размещают слева.
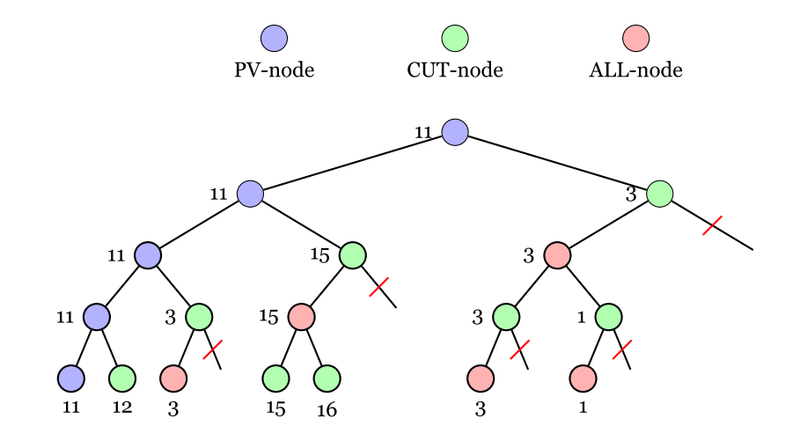
Таково классическое деление дерева перебора по типам узлов в системах с альфа-бета отсечениями. В современных программах типы узлов понимают немного иначе, но мы обсудим это позже. |
|
|
| номер сообщения: 54-72-8245 |
|
|
|
|
Альфа-бета отсечения - это один из немногих методов отсечений без потерь, то есть он выдает тот же ход и оценку, что и полный перебор на ту же самую глубину. Иначе говоря от его использования мы ничего не теряем, но существенно выигрываем во времени. Сокращение перебора в дереве вариантов от использования метода составляет около квадратного корня от количества позиций для полного перебора (это очень много, например одна минута вычислений вместо одного года).
Достаточно очевидно, что так как альфа-бета как бы "перепрыгивает" глубину через одну, то даже с идеальными сортировками сама по себе она не в состоянии увеличить глубину более чем в два раза, по сравнению с полным перебором. То есть метод имеет свои ограничения. Тем не менее он позволяет сократить количество рассматриваемых вариантов в каждой позиции с 30 - 40 возможных, до 11 - 14 только альфа-бетой, а при хорошей сортировке ходов приблизиться к теоретическому пределу альфа-беты - около 6 вариантов в среднем на позицию. Это уже дает возможность при наличии вычислительного ресурса хотя и с трудом, но увеличивать глубину. При полном переборе это было бы практически невозможно.
Подобный поиск был типичным для программ с конца 70-х и до конца 80-х годов. Используя также хеш-таблицы (таблицы перестановок для повторяющихся позиций) программы сокращали ветвление вариантов до 5,5 на переборную позицию.
Начиная с Каиссы 1972, которая лет на 5 опережала свое время и заканчивая Дип Блю 1997, который четверть века спустя примерно на столько же отставал, отсечения выполнялись преимущественно альфа-бетой с сортировками. Еще в 80-е было показано (а предполагалось и ранее), что сила программ быстро растет с увеличением глубины, особенно на первых порах. Этот рост составляет примерно 150 - 200 пунктов рейтинга на каждую единицу глубины, что почти равно одному шахматному разряду. Учитывая, что прогресс качества оценочной функции как в те времена, так и позднее был невелик, а методы отсечений с потерями до начала-середины 1990-х ещё не играли особой роли, то сила программ была обычно пропорциональна глубине до которой они досчитывали.
На этом и базировалась идея Дип Блю - используя сверхбыстрые специализированные микросхемы и распараллеливание, достигнуть уровня чемпиона мира. Но так как дерево перебора все равно растет очень быстро, то даже при ветвлении 5,5 (а на самом деле почти 8 из-за потерь на распараллеливание и прочих факторов) огромные и по современным меркам мощности Дип Блю не позволяли ему углубиться дальше 12 полуходов итеративного перебора. |
|
|
| номер сообщения: 54-72-8246 |
|
|
|
|
Тем не менее альфа-бета отсечения привели к огромному прогрессу в силе игры. Например, если бы Дип Блю использовал действительно полный перебор, то его глубина сократилась бы до 7 полуходов и играл бы он не сильнее первого шахматного разряда.

Давайте теперь взглянем непосредственно на цифры. Например, Каисса 1972 года вычисляла около 200 позиций в секунду, почти досчитывала до глубины 5 полуходов в середине партии и оценочно играла на 1700 - 1800 пунктов рейтинга. Это уровень 1 - 2 шахматного разряда.
Далее пошло по нарастающей. Программы буквально "выгрызали" каждую следующую глубину. Чтобы увеличить глубину на один полный ход (т.е. два полухода, белых + черных), машину требовалось ускорить примерно в 5,5^2 = 30 раз. На два хода - в тысячу раз, на четыре хода - в миллион раз и т. д.
Быстрый прогресс в микроэлектронике позволил резко увеличить скорость, переход на специализированное железо увеличил ее еще на несколько порядков, сколько-то добавило распараллеливание. И результат пришел. Программам (читай - Дип Блю) все-таки удалось дотянуться до высшего уровня. Смотрим:
1976г. Каисса - 200 поз/сек, глубина 5, рейтинг 1800, I - II разряд
1983г. Белле - 100 тыс.поз/сек, глубина 8, рейтинг 2200, кмс-мастер спорта
1989г. Дип Сот - 700 тыс.поз/сек, глубина 10, рейтинг 2550, гроссмейстер
1997г. Дип Блю - 125 млн.поз/сек, глубина 12, рейтинг 2800, чемпион мира
Цифры выше не совсем бьются, но нужно учесть, что не смотря на принципиальную схожесть алгоритмов перебора, программы все-таки были разные. Кроме того, числа здесь разной точности, полученные в разное время, разными людьми и некоторые из них оценочного характера.
Для более поздних программ сравнение по глубине уже не работает. Его нельзя проводить, поскольку в ведущих программах началось использование методов отсечений с потерями, и к примеру, чтобы играть на рейтинг 2800 требовалось считать уже на 15 - 16 единиц итеративной глубины. То есть дополнительные отсечения пришлось компенсировать увеличением глубины по основным линиям. Но зато они позволили уменьшить требования к скорости компьютеров и уровня 2800 достигли уже обычные персоналки. |
|
|
| номер сообщения: 54-72-8247 |
|
|
|
|
*****
С начала-середины 1990-х появились и начали набирать популярность отсечения методом нулевого хода (Null Move Pruning, NMP). Уже к концу столетия ни одна серьезная программа не обходилась без них.
Давайте теперь добавим нулевой ход на общее дерево перебора на схеме выше, для чего отметим на нем кроме альфа-бета отсечений, еще и те ходы (ветви), которые принципиально возможно отсечь с помощью NMP. По сравнению со схемой NMP из предыдущей части значок отсечений намеренно сдвинут на уровень вниз, для большей наглядности. На пунктирных линиях возможные отсечения не показаны, дабы не загромождать схему:
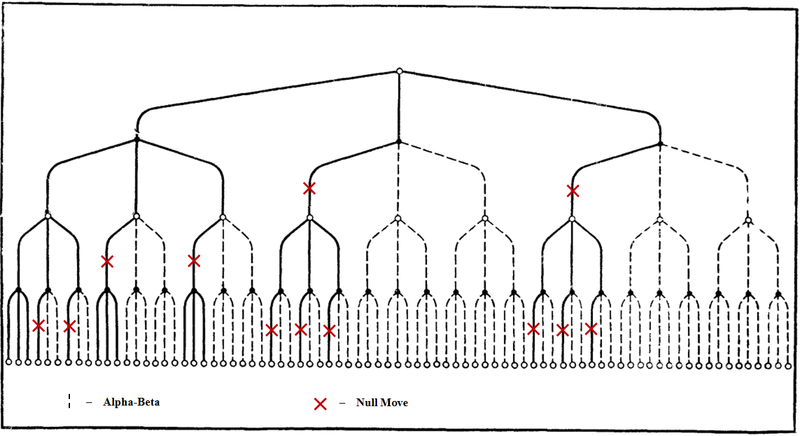
Как мы видим, отсечения посредством нулевого хода происходят только на Cut-nodes, аналогично альфа-бете. Это происходит, потому что нулевой ход тоже отсекает по превышении беты. Но если альфа-бета может отсекать на Cut-nodes все ходы кроме первого (альфа-бета обязана его просмотреть на полную [заданную] глубину, чтобы принять решение об отсечении), то нулевым ходом можно отсекать и первый ход на этих узлах. В этом отношении мы можем даже условно рассматривать нулевой ход, как нулевой по сортировке. В таком случае сам термин "нулевой ход" - изначально неудачная калька при переводе с английского, даже обретает некоторый смысл.
Нулевой ход производит отсечения окончательно. Если выполнить отсечение выше по дереву, то ветка ниже рассматриваться уже не будет, и очевидно, что нижние отсечения не состоятся. По крайней мере до следующей итерации, где перебор вернется в тот же узел. Поэтому если произошло отсечение выше по схеме, то нижние значки NMP-отсечений "недействительны". Но отсечения нулевым ходом происходят не всегда, поэтому в свою очередь, если отсечения выше нет, то они возможны ниже по дереву.
Еще можно отметить, что несмотря на то, что отсечения происходят на Cut-nodes, нулевой ход прежде всего предотвращает появление в дереве All-nodes. По грубой прикидке методом нулевого хода отсекается примерно 60% из всех потенциальных All-nodes.
Именно отбрасывание All-nodes в первую очередь позволяет производить дальнейшее сокращение ветвления (branching factor) у программ. На рубеже веков введение и совершенствование нулевого хода позволило снизить ветвление с типичного в конце 80-х значения 5,5, до гораздо меньшего 3,5. Это позволило играть на уровне Дип Блю и топ-гроссмейстеров даже программам запускавшимся на рабочих станциях на скорости всего 3 - 4 млн.поз/сек. В то же время нулевой ход, это метод отсечений с потерями информации, а значит программам необходимо было наращивать глубину до 15 - 16, чтобы достичь уровня Дип Блю, который считал до глубины 12, но не упускал ни одного полезного хода.
После пропуска хода NMP-отсечения выполняются не сразу, а производится некоторый пробный перебор на сокращенную глубину. Это позволяет повысить надежность отсечений, но в то же время не сильно увеличивать объем перебора. Программы 00-х обычно сокращали глубину пробного перебора всего на 3 полухода при общей глубине 15 - 16. Кажется немного, но экономия могла достигать 6 х 6 х 6 = 216 раз. А учитывая рекурсивное исполнение, пробный перебор проводился в значительной степени "бесплатно", не слишком перегружая компьютер и в то же время обеспечивая солидную надежность. В настоящее время величина сокращений регулируется динамически и они могут сильно варьироваться в зависимости от обстоятельств.
Пробный перебор не включается в основное дерево перебора, поскольку пропускать ходы не по правилам шахмат. Он только определяет - производить отсечение или нет. При этом нулевой ход допускает рекурсивное исполнение, то есть после нулевого хода в дереве пробного перебора допускается снова выполнять нулевой ход неограниченное число раз, пока это позволяют условия. Но конечно не подряд.
Если пробный перебор показал, что отсечение нулевым ходом возможно, то проводится еще верификационный перебор - из той же позиции и тоже на сокращенную глубину. В нем уже не будет пропуска хода. Такой перебор необходимо произвести, чтобы исключить возможность цугцванга, когда нулевой ход использовать нельзя, поскольку сам принцип нулевого хода опирается на преимущество права выступки. А при цугцванге право хода является фатальным недостатком позиции.
Соответственно, нулевой ход не применяется в играх, где право выступки не дает заметного преимущества. Например в шашках, где оппозиция важнее права на ход. В шахматах нулевой ход также не допускается, когда с нашей стороны на доске не остается фигур, кроме пешек. Шахматы без фигур по сути превращаются в шашки, поэтому значение оппозиции тоже становится решающим. В шашках же место нулевого хода заняли MultiCut или ProbCut, тогда как в шахматах эти методы находятся на вторых ролях. Но мы их тоже рассмотрим, когда углубимся в код поиска Стокфиша.
Отсечения методом NMP не состоятся, если пробный перебор не выявит превышения беты или верификационный перебор выявит некорректность нулевого хода, или же изначально в программе не будут выполнены условия для запуска нулевого хода. В таких случаях придется проводить обычный перебор, как описано в предыдущей части. Конечно, пробный и верификационный перебор, это дополнительный перебор, но выгода от использования NMP настолько велика, что небольшой дополнительный перебор с лихвой компенсируется отсечениями в дереве на неосновных ветках.
Надо понимать, что при нулевом ходе пробный перебор будет проведен в любом случае, независимо от того произведет он отсечение или нет. Поэтому, любые оптимизации на нем желательны. Чтобы такой перебор не стал напрасным избыточным счетом, обременяющим основной перебор, помимо использования рекурсивного исполнения и сокращенной глубины его также желательно проводить в тех областях дерева, где отсечения могли бы произойти наиболее часто. Для этого используется ряд правил. Например, NMP рассматривается только для позиций со статической оценкой больше беты. Логика в том, что позиции уже имеющие высокую оценку, даже после пропуска хода в целом сохранят ее и с большей вероятностью отсекутся.
Но мы немного забежали вперед. Отложим вопросы программирования до тех пор, когда непосредственная реализация методов будет проиллюстрирована на примерах кода. А пока перейдем к LMR. |
|
|
| номер сообщения: 54-72-8248 |
|
|
|
|
*****
Сокращение на поздних ходах (LMR) начало набирать популярность с середины 00-х, когда появились использующие его сильные программы с открытым исходным кодом - Фрукт и Глаурунг. В первую очередь благодаря LMR, с годами степень ветвления в дереве перебора программ постепенно сократилась с 3,5 до 2. В современных программах она опустилось ниже 1,5. Конечно помогают и другие методы, но все же LMR является определяющим в данном вопросе.
Аналогично тому как мы поступали ранее, укажем LMR на общем дереве перебора в дополнение к отсечениям альфа-бетой и нулевым ходом. Варианты пунктиром из Cut-nodes считаем отсеченными альфа-бетой. Поэтому для наглядности возможный LMR на них отображать не будем:
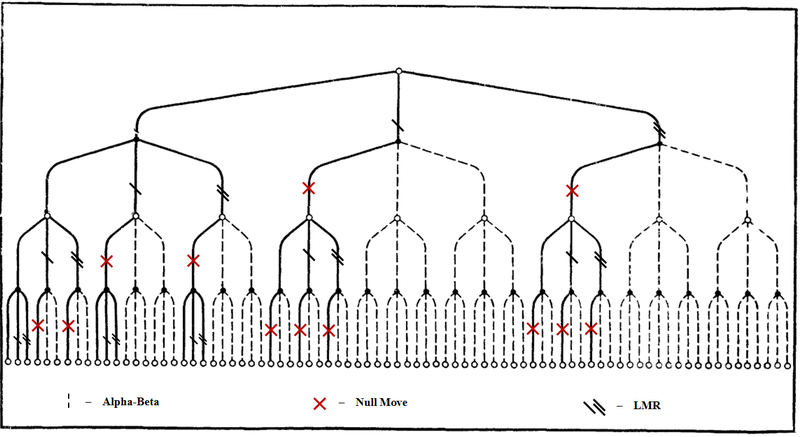
В отличие от нулевого хода LMR не отсекает ветку окончательно, а лишь сокращает глубину перебора на ней. Поэтому на ветке варианта возможно выполнять LMR по нескольку раз. То есть, если на схеме произошло сокращение глубины выше по дереву, то далее его можно произвести и ниже по дереву, если конечно позволяют условия. Отсечения нулевым ходом после LMR тоже возможны.
Если нулевой ход действительно отсекает 60% All-nodes, то на остальных All-nodes отсечений не происходит и при иных обстоятельствах на них пришлоcь бы считать все продолжения. В самом деле - альфа-бета здесь не работает, а отсечение нулевым ходом отклонено. Поэтому самым важным методом сокращения перебора на этих узлах становится LMR. Именно здесь происходит основное снижение ветвления. В то время как на Cut-nodes до LMR доходит лишь в третью очередь, то на All-nodes, не отсеченных нулевым ходом, LMR очень значимо сокращает величину перебора.
*****
Давайте подведем некоторые итоги. Как мы видим, на Cut-nodes отсечения происходят фактически сразу. На практике альфа-бета обычно отсекает здесь после рассмотрения первого или второго хода, конечно если ранее уже не произошло отсечение нулевым. В свою очередь, значительная часть All-nodes отсекается нулевым ходом, а на всех остальных All-nodes происходит резкое сокращение глубины вследствие использования LMR. Таким образом эти три метода дополняя друг друга, отсекают, отсекают и отсекают, доводя дерево перебора чуть ли не до голого ствола.
Но кроме трех основных, существуют так же и другие методы, которые в совокупности тоже вызывают очень даже немало отсечений. Некоторые из них мы рассмотрим в следующей части. Так же проясним кое-какие важные термины и коснемся иных вопросов.
Продолжение следует... |
|
|
| номер сообщения: 54-72-8249 |
|
|
|
|
Шахматные программы IV. Термины и методы
В этой части мы коснемся некоторых наиболее ходовых понятий, которые часто используются в терминологии компьютерных шахмат и без которых затруднительно конструктивное обсуждение вопросов перебора. Также рассмотрим некоторые второстепенные методы направленного перебора, которые тем не менее глубоко интегрированы в структуру поиска. И в концовке обсудим общий порядок обхода всего дерева перебора целиком.

Представленная здесь информация на первых порах может показаться не такой уж и важной, но если в дальнейшем планируется углубиться в код поиска реальных программ, то она поможет прояснить некоторые вопросы. |
|
|
| номер сообщения: 54-72-8250 |
|
|
|
|
Наглядным пособием нам будет служить схема, которая приведена ниже. В ее основе лежит схема LMR из II части, но расширенная в глубину на один полуход и приведенная ближе к стандартам реальных программ. Перебор, как обычно, стартует с основного варианта (PV) по левой ветке, затем переходит на среднюю, где обычно происходят отсечения, и т. д.
В первую очередь следует прояснить, что означают альфа и бета. Альфа (alpha) - это "наша" лучшая оценка в какой-то из ранее просмотренных веток. То есть оценка нашего лучшего варианта, который у "нас" есть в наличии. В то же время это та оценка, к которой мы можем обратиться в случае, если текущая ветка, в которой мы ведем перебор, не оправдает наши ожидания из-за получения в ней низкой оценки. В таком случае мы всегда можем ее избежать, выбрав ветку, где получена альфа.
Бета (beta) - аналогичная оценка "для противника" полученная где-то выше и в другой ветке по дереву перебора. Все варианты с оценкой выше беты с нашей точки зрения "слишком хороши, чтобы быть правдой", поскольку соперник точно так же может их избежать, так как имеет возможность выбрать вариант по другой ветке с оценкой пониже. Именно потому варианты с оценкой выше беты отсекаются альфа-бета процедурой, методика которой подробно расписана во II части.
Здесь существует один важный нюанс, о котором уже упоминалось ранее. В реальных программах используется негамаксная процедура выбора хода, поскольку она проще для написания и вычислений. Она позволяет использовать унифицированную строку поиска независимо от глубины и отсекать всегда по превышению беты. Согласно нее, каждая позиция рассматривается с точки зрения того, чей ход в ней. То есть по мере углубления сторона "за нас" и "за противника" постоянно меняются местами. Иначе говоря, как бы мы ни углублялись по дереву, каждая следующая позиция всегда "за нас", а выше и ниже "за противника". Поскольку меняются местами стороны, то приходится менять местами и их оценки. Альфа становится бетой, а бета альфой. На следующем полуходе глубины они снова поменяются местами и т. д.
Если рассматривать каждую позицию с точки зрения того кто имеет право хода и отсекать всегда по превышению беты, то нужно учесть, что приоритеты сторон противоположны и они стремятся улучшить каждый свою оценку в разных направлениях шкалы оценок. Но при углублении, и соответственно смене сторон, необходимо сохранять принцип - чем больше оценка, тем лучше. Поэтому каждый раз при смене стороны нужно менять и знак оценки. Плюс становится минусом, а минус плюсом. При дальнейшем спуске по дереву знак снова изменится, и т. д.
Для примера, так выглядит заголовок функции основного поиска Стокфиша:
search(Position& pos, Stack* ss, Value alpha, Value beta, Depth depth, bool cutNode)
А так, строка рекурсивного перебора в ней:
value = -search(pos, ss + 1, -beta, -alpha, newDepth, false);
При расчете на следующую глубину ветки, альфа заносится вместо беты, а бета вместо альфы. Обе оценки берутся с противоположным знаком. Когда же из перебора по данной ветке нам вернется оценка, ей необходимо возвратить правильный (то есть противоположный, -search) знак. Таким образом, знак оценки снова изменится. Конечно, пять инверсий на одну строку может немного сбивать с толку.
Для большей наглядности эти и другие изменения проиллюстрированы ниже на схеме. Схема по большей части заимствована из описания LMR во II части, но знак оценки изменяется соответственно правилам негамакса. Аналогично меняются местами и лучшие оценки каждой из сторон - альфа и бета.
Вначале, когда перебор начинает осуществляться по левой ветке, ни своих, ни оценок противника у нас еще нет. Поэтому альфа принимается равной наименее возможному значению, то есть минус бесконечности. Бета соперника соответственно будет приравнена к плюс бесконечности. Далее, по мере получения оценок позиций альфа ("наша" оценка, или иначе говоря, оценка той стороны, чей ход в рассматриваемой позиции), будет повышаться, а бета понижаться. Каждое следующее улучшение оценки увеличивает альфу, а улучшение оценки у противника уменьшает бету.
Допустим, на схеме ниже после исследования варианта слева мы получили его оценку, +5. Это наша альфа. То есть альфа стороны, которая ходит из верхнего узла (позиции). Таким образом, альфа повышается от минус бесконечности до +5. Бета не изменилась, так как ход соперника пока неизвестен, поэтому бета по-прежнему приравнена к плюс бесконечности. Вариант временно становится нашим основным вариантом (PV), и он таковым останется, если только мы не найдем варианты с большей оценкой.
Переходим ко второму варианту, углубляемся на один полуход. Здесь мы смотрим на позицию с точки зрения соперника. Наша альфа стала для соперника бетой. Оценка, которая лучше для нас, хуже для него. Поэтому меняем знак оценки на противоположный. То есть прежняя альфа, теперь бета с переменой знака. Поскольку ни одного продолжения еще не оценено, то альфа в узле, тоже со сменой знака, пока минус бесконечность. |
|
|
| номер сообщения: 54-72-8251 |
|
|
|
|
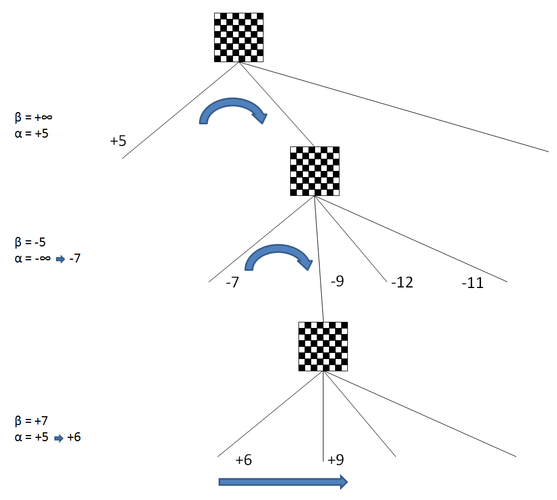
Чем ниже бета, тем чаще будут происходить отсечения. А поскольку отсечения это основной способ ограничения перебора, и соответственно роста силы игры, то низкое значение беты становится ключевым фактором.
Так как при углублении по дереву на один полуход альфа и бета меняются местами, т.е. альфа становится бетой, то повышение альфы не менее значимый фактор. Наконец, альфа ведь повышает "нашу" оценку позиции, что улучшает "наши" шансы на победу в партии.
После просмотра первого ответа, мы получаем лучший ход соперника, его альфу. Альфа узла поднимается от минус бесконечности до -7. В данном случае оценка лучшего хода в позиции и альфа равны, но так бывает далеко не всегда.
Далее смотрим второй ответ. На схеме он расширен в глубину. Кстати сказать, мы точно так же смотрели и ветку основного варианта, и первого ответа, просто для наглядности перебор в них на схеме не отображается.
Перейдя вниз по ветке второго ответа, мы аналогично меняем местами стороны, а значит альфу с бетой и знак оценки. Теперь альфа опять стала +5. В этой позиции по мере перебора альфа повышается с +5 до +6, но отсечения не происходит, поскольку оценка лучшего хода меньше беты (+7). Продолжая перебор, мы достигаем хода с оценкой +9. Поскольку эта оценка выше беты, то производим отсечение, не рассматривая остальные ходы. На уровень выше поднимаем оценку +9.
Не забываем менять знак, так как уровнем выше соперники поменялись местами. Таким образом оценка второго ответа равна -9. Она меньше оценки лучшего ответа (-7) на этой глубине и меньше альфы (-7), поэтому альфа не меняется. Далее переходим к изучению третьего ответа. Перебор продолжается аналогичным образом.
 |
|
|
| номер сообщения: 54-72-8252 |
|
|
|
|

*****
Интервал в оценках между альфой и бетой называется "окно" (window). Как уже упоминалось выше, в начале перебора альфа и бета принимаются равными бесконечности. Но так как отсечения происходят по превышению беты, а та равна бесконечности, то поначалу отсечения идут не очень активно. Дерево перебора очень большое, движок тормозит - бесконечность вообще не превысить, а по получении первых оценок значение беты обычно все еще слишком высоко для частых отсечений.
Прежде чем бета понизится до значений близких к реальным, программа произведет много лишних вычислений, которых при иных обстоятельствах можно было бы избежать. Поэтому для ускорения в начале перебора используют метод Aspiration windows.
В этом случае оценки альфы и беты спекулятивно принимают близкими к более реально ожидаемым значениям. Отсечения пойдут намного быстрее. Но, в свою очередь, если при таком переборе границы будут превышены, то перебор придется проводить заново на полном интервале.
Тем не менее, спекулятивное уменьшение размера окна все равно выгоднее с точки зрения экономии расчетов. Изначально программа выбирает интервал исходя из предыдущего перебора, если таковой проводился. Современные программы при выходе за пределы окна просто немного расширяют или сдвигают спекулятивный интервал.
Таким образом, чем меньше разница между альфой и бетой, тем быстрее производятся отсечения. По мере перебора альфа и бета сближаются друг с другом. Если бы "окно" между ними было минимальным, то альфа-бета отсечения производились бы наиболее эффективно.
На этом основан метод Principal Variation Search (PVS). Мы можем использовать тот факт, что если первым ходом по сортировке отсечения не произошло, то для остальных ходов его скорее всего тоже не будет, если конечно сортировка корректна. Таким образом, в большинстве случаев оценка будет меньше альфы, а следовательно и беты. Мы можем провести перебор первого хода по сортировке с полным окном, а затем спекулятивно понизить значение беты до значения альфа+1 для второго и последующих ходов - окно станет минимальным и перебор ходов с номером по сортировке >1 пойдет быстрее. Если же какой-то из поздних ходов неожиданно превысит альфу, а значит и нашу недостоверную бету, тогда произведем его перерасчет с полным окном. Редкие повторные переборы при превышении альфы потребуют гораздо меньше расчетов.
В этом отношении метод PVS похож на LMR. Аналогично он производит упрощенный перебор ходов, которые почти наверняка не улучшат оценку, но потребуют много ресурсов для вычислений. PVS дает гораздо меньший эффект, чем LMR, поскольку лишь ускоряет альфа-бета отсечения. Но зато PVS не провоцирует некорректные отсечения. Его условно можно рассматривать как один из методов сортировки, но с предварительным перебором.
В другом отношении PVS выполняет ту же работу, что и Aspiration windows. Он так же спекулятивно манипулирует размером альфа-бета окна. Аналогично, по превышении альфы оценка становится недостоверной и происходит повторный перебор с полным окном. Но если Aspiration windows используется только в начале перебора, то PVS можно использовать повсеместно. Метод применяется практически при каждом вызове функции поиска (search) с номером хода >1.
Строка поиска с PVS, на ходах после первого по сортировке, выглядит примерно так:
value = -search(pos, ss + 1, -(alpha + 1), -alpha, newDepth, !cutNode);
Как видим, окно здесь минимальное. Бете присвоено значение альфа+1.
Итак, при использовании PVS, первый ход по сортировке в каждой позиции дерева рассматривается с полным окном, а остальные с минимальным (нулевым).
Со временем PVS еще более усовершенствовали. Теперь полное окно в некоем поддереве используется только один раз - это происходит в "левой" линии из головной позиции поддерева, а все остальные ходы рассматриваются с минимальным окном. Но конечно по превышению альфы и повторном переборе узлы будут переоценены, и типы окон в ветках поддерева могут измениться.
С введением PVS оценка типов узлов тоже поменялась. В современных программах типы узлов определяются несколько иначе, чем по классической схеме. Например в Стокфише к PV-node приравнены все узлы, которые рассматриваются с полным окном, а не только цепочка узлов из корневой позиции. Так что PV-node здесь чуть ли не синоним полного окна. В свою очередь все узлы с минимальным окном относятся к типу NonPV, в составе которого чередуются Cut- и All-nodes. На All-nodes появляется бета, но это спекулятивная бета - в любом случае при превышении альфы, а значит и данной беты, будет произведен перерасчет с полным окном.
Здесь пожалуй стоит прерваться. Мы как-то слишком рано углубились в частные вопросы реализации PVS. За подробностями отсылаю на Chessprogramming wiki:
https://www.chessprogramming.org/Principal_Variation_Search |
|
|
| номер сообщения: 54-72-8253 |
|
|
|
|
*****
Еще один способ ускорить программу носит в основном технический характер.
Немного неожиданно, но одним из самых ресурсоемких процессов в ходе перебора является банальная генерация ходов. То есть определения, какие в каждой позиции вообще существуют ходы, разрешенные правилами. Спускаясь по дереву в каждую новую позицию, программа в первую очередь должна найти в ней все ходы, чтобы запустить процесс сортировки. Но бОльшая часть возможных ходов в позиции в современных программах обычно отсекается. Тогда получается, что их генерация по большей части напрасна, так как они в основном даже не рассматриваются.
Решить эту проблему позволяет реализация генерации ходов "порционно" - это так называемая инкрементальная генерация ходов (Incremental move generator). Ходы генерируются частями, по ходу процесса сортировки. Сначала "выгодные взятия", затем киллеры и т. д. Но даже в современных программах генерация ходов по-прежнему отнимает немало ресурсов. Хотя, конечно, сейчас упор в вычислениях несколько сдвинулся в сторону нейросети и она в первую очередь становится "бутылочным горлышком" для скорости перебора.
Чтобы генератор ходов работал быстро, важно правильное представление шахматной доски в программе. Иначе говоря, записи позиции в таком виде, которая наиболее удобна для быстрой обработки компьютером. В настоящее время среди ведущих программ безраздельно господствует побитовое представление доски, называемое битбордами. Или точнее его модификация "Магические битборды" (Magic Bitboards).
Тип представления доски в программе очень важен для скорости и занимает значительную часть кода. Но поскольку эта часть программы носит больше технический характер, то ее описание выходит за пределы тематики данной статьи. Поэтому ограничусь только ссылками на статью о магических битбордах в wiki:
https://www.chessprogramming.org/Magic_Bitboards
и обзорную статью Владимира Медведева (WinPooh):
https://drive.google.com/file/d/10cM5-RwXatSpZxSZGAV6AhwjyTbnurRH/view |
|
|
| номер сообщения: 54-72-8254 |
|
|
|
|
*****
Теперь, когда мы немного разобрались с организацией перебора в реальных программах, попробуем взглянуть на все дерево перебора целиком. В частности надо разрешить вопрос, в каком порядке обходить это самое дерево. Взглянем на схему ниже:
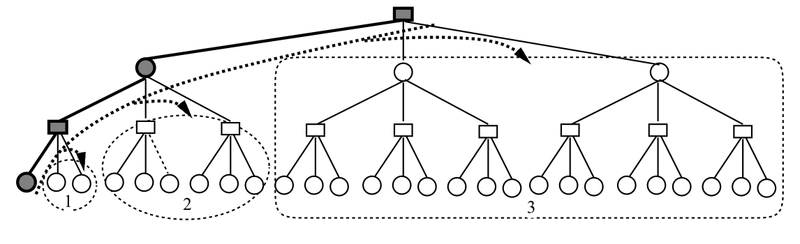
Обход дерева происходит следующим образом. Перебор начинается с корневого (верхнего) узла. Вследствие рекурсивного вызова функции программа сначала углубляется по ветке основного варианта до заданной глубины, где получает числовую оценку позиции с помощью QS и оценочной функции. На схеме эта ветка находится слева.
Потом программа исследует соседние с той позицией варианты (1). Затем она переходит в ветку с менее близким соседством, где исследует варианты (2) аналогичным образом. Конечно большая часть из этих вариантов отсекается. Далее программа через дерево переходит к еще менее близким вариантам (3) и т. д. Получается своеобразный каскад. Основной вариант берется из предыдущих вычислений, а если таковых нет, то подбирается оценочным или случайным образом.
Когда программа завершает обход всего дерева, перебор на заданную глубину считается законченным. При этом находится или подтверждается основной (лучший) вариант.
Затем программа повторяет процедуру. Из корневой позиции она снова спускается по основному варианту, продляет его на один полуход глубины и аналогично обходит все дерево. По сути перебор начинается заново - теперь программа снова обходит дерево по известным правилам, но с добавлением единицы глубины. Основной вариант, который суть цепочка лучших ходов по мнению программы, с предыдущего раза может измениться, но чаще всего он остается прежним.
Такой метод обхода дерева называется итеративным углублением (Iterative deepening). За каждую итерацию перебора глубина прирастает на один полуход. По веткам производятся еще различные дополнительные продления и сокращения, согласно некоторым правилам. Но в счете итеративной глубины они не учитываются, поэтому в современных программах реальная глубина ветки может существенно отличаться от номинальной (итеративной) глубины.
Может показаться, что такой метод не слишком эффективен, поскольку для достижения каждой следующей глубины программе нужно снова обойти все дерево. Но как ни парадоксально повторный обход дерева позволяет ускорить перебор.
На практике перебор происходит быстрее, чем если бы мы сразу считали на большую глубину. Заполняются таблицы перестановок, истории и т. д., и с каждой следующей итерацией производится намного, намного больше отсечений. Предыдущая итерация выполняет функции предварительного перебора, который кратно уменьшает величину перебора для следующей итерации.
Кроме того, перебор сразу на большую глубину может затянуться, поскольку нельзя заранее предсказать, в каких ветках будет много отсечений, а в каких нет. Такой перебор нельзя прерывать до окончания обхода дерева, иначе некоторые ветки останутся совсем без рассмотрения. Итеративное углубление позволяет решить эту проблему. Между итерациями перебор всегда можно прервать, а если нужно остановиться немедленно, то всегда можно взять результаты с предыдущей глубины. Это позволяет относительно гибко регулировать время отпущенное на ход, что важно в соревнованиях и тестах.
Еще одно преимущество заключается в экономии оперативной памяти, так как не нужно хранить в памяти все дерево целиком, поскольку мы его постоянно переобходим. Достаточно ограничится только цепочкой ходов основного варианта, чтобы программа знала с какого варианта начинать углубление каждый следующий раз, а далее варианты просматриваются по известным правилам. Если в процессе перебора основной вариант изменился, то старый отбрасывается и запоминается новый. Его и будем использовать при начале перебора на следующей глубине. Такой способ обхода дерева называется Depth-First.
Этот подход был особенно ценен при разработке ранних шахматных программ, когда каждый байт памяти был на счету. Но это важно и сейчас, когда деревья перебора выросли до огромных размеров. Поэтому такой способ обхода дерева используют все движки на классической базе. Конечно некоторое количество позиций хранится в хеш-таблицах, но их число очень ограничено, кроме того, каждая позиция хранится по отдельности и они не образуют единого дерева.
Напротив, обход дерева методом Монте-Карло (MCTS), который применяла Альфа Зеро, относится к подходу Best-First, где решение о том, какой вариант углубить в первую очередь, принимается после окончания предыдущего углубления. Выбор производится по оценке и некоторой статистике, которая обновляется после подведения итогов предыдущего углубления и потому следующий пролонгируемый ход нельзя знать заранее. Поскольку мы не знаем, какую цепочку ходов будем продлять дальше, то для этого требуется хранить все дерево перебора в памяти целиком. Все его позиции и связи между ними.
При таком подходе оперативная память быстро заканчивается, и потому не позволяет хранить большие деревья позиций. Соответственно для скоростных движков на классической базе (и их больших деревьев) этот метод практически бесполезен. При необходимости выделить даже всего несколько байт на позицию, десятки миллионов позиций в секунду при переборе быстро приведут к исчерпанию памяти компьютера.
И еще один момент. В описании выше мы неявно предполагали, что по достижении заданной глубины перебор прерывается и вызывается оценочная функция. Но на самом деле сначала вызывается функция форсированного варианта Quiescence Search (QS) и только потом производится оценка позиции. Обоснования такого подхода мы коснулись в концовке I части.
Хотя по своей сути QS и относится скорее к продлениям, оценку которую он возвращает, традиционно принято считать динамической оценкой позиции. Поэтому, кроме специальных случаев, далее так же будем поступать и мы. |
|
|
| номер сообщения: 54-72-8255 |
|
|
| |
|
|
|
|
|
|
|
| Copyright chesspro.ru 2004-2026 гг. |
|
|
|